Index
Prototyp einer self-managed Multi-Cluster-Architektur für die Edge (BA/PA/MA)

Der Einsatz von Edge Computing gewinnt in vielen Bereichen an Bedeutung, da er die Datenverarbeitung näher an den Ort der Datenentstehung verlagert und damit Latenzen, Bandbreitenbedarf sowie Abhängigkeiten von Cloud-Verbindungen reduziert. Gleichzeitig steigen die Anforderungen an Automatisierung, Lifecycle Management und Fleet Operations, weil Edge-Knoten oft heterogen sind, in instabilen Netzen laufen und nur eingeschränkt an verteilten Ort gewartet werden können.
Ziel dieser studentischen Arbeit ist der Aufbau und die prototypische Evaluation einer self-managed Edge-Kubernetes-Referenzarchitektur (hub-and-spoke), die zunächst virtuelle Edge Devices (VMs auf Proxmox VE und/oder OpenStack) nutzt und später auf dedizierte Hardware übertragbar ist. Im Fokus steht eine reproduzierbare Day-0 Provisioning Pipeline via (i)PXE boot sowie first-boot configuration mit cloud-init und Ignition/Combustion (optional unter Nutzung von Matchbox). Darauf aufbauend sollen mehrere Linux- und Kubernetes-Cluster-Varianten automatisiert gestartet und zentral mit GitOps sowie Fleet-style Multi-Cluster Rollout verwaltet werden.
(Mögliche) Schwerpunkte der Arbeit:
- Design & Implementierung einer hub-and-spoke Referenzarchitektur für self-managed Edge Kubernetes (Management Cluster + Edge Spokes).
- Provisioning Pipeline: Klassisches (i)PXE, darauf aufbauendes Netboot mittels HTTPBoot via UEFI or U-Boot oder je nach BMC auch IPMI/Redfish, Profilverwaltung (optional Matchbox) und Konfiguration via Ignition/Combustion/cloud-init. Parallel dazu Lifecycle Management mittels Cluster API und entsprechendem Provider (z.B. CAPM3 (Metal³ im Falle OpenStack Ironic) oder CAPT (Tinkerbell im Falle von einfachem iPXE/Netboot))
- Definition von stabilen Cluster-Profilen (z.B. Talos Linux, openSUSE Leap Micro + k3s, Ubuntu + MicroK8s oder Debian + k0s) inkl. automatisiertem Bootstrap und Re-Provisioning (replaceable nodes).
- GitOps-gestützte Baseline: Standardisierte Installation von Add-ons (z. B. Longhorn, Ingress, Observability) über Argo CD oder Flux.
- Persistence & Registry Integration: Longhorn als persistence storage, Deployment-Pipeline über GitLab CI/CD, GitLab Container Registry, Harbor als Proxy Cache und Replication Bridge / Pull-Through Cache (ggf. zunächst lediglich GitLab Dependency Proxy für Docker Hub) und optional K3s Spegel.
- Dokumentation & Demonstrator: Nachvollziehbare Architektur-/Betriebsdokumentation, IaC/Automation in einem Git-Repository sowie eine Demo-Umgebung als Testbed für Forschung/Lehre.
Ausblick auf darauf aubauende Arbeiten:
- Erweiterung des Lifecycle Managements um Foreman und Katello.
- Fleet-style Multi-Cluster Rollout: Vergleich und Bewertung von Rancher Fleet, Argo CD ApplicationSet und Flux (optional Open Cluster Management (OCM) / Karmada) anhand definierter Kriterien (Drift, Skalierbarkeit, Multi-tenancy, Offline-Toleranz, Usability usw.).
- Integration und Reifegradbewertung von KubeEdge/OpenYurt oder LF Edge Komponenten (FIDO Device Onboard, EVE-OS, EdgeX Foundry) im Rahmen der bestehenden Architektur.
Wenn die ausgeschriebene Arbeit noch online ist, dann ist sie auch noch aktuell. Sollten Sie Interesse an der Arbeit haben, so kommen Sie bitte mittels einer E-Mail (in der Sie kurz Ihr Vorwissen darstellen) auf mich zu. Sollten Sie eine intrinsische Motivation für ein angrenzendes oder ähnlichen Thema haben, so stellen Sie in Ihrer Anfrage bitte den Bezug zu meiner Ausschreibung dar.
Bitte stellen Sie die komplette Anfrage in deutscher Sprache, auch wenn Sie die Ausarbeitung in Englisch verfassen werden. Hintergrund ist, dass Sie sich in laufende Forschungsprojekte einbringen mit den Unternehmen austauschen können sollen und von diesen wird mehrheitlich eine Kommunikation auf Deutsch gewünscht.
Weitere Informationen erhalten Sie auf Anfrage, der Arbeitsumfang kann entsprechend der Arbeit angepasst werden und die Bearbeitung weitestgehend im Home-Office stattfinden.
Realisierung eines Mixed-SBC-Clusters für die Edge (BA/PA/MA)
Der Einsatz von Edge Computing gewinnt in vielen Bereichen an Bedeutung, da er die Datenverarbeitung näher an den Ort der Datenentstehung verlagert und damit Latenzen, Bandbreitenbedarf sowie Abhängigkeiten von Cloud-Verbindungen reduziert. Ein Mixed-SBC-Cluster, der verschiedene Single Board Computer (SBC) wie Nvidia Jetson, Raspberry Pi und verschiedene Hardwareerweiterungen umfasst, bietet eine ausgezeichnete Plattform, um die Herausforderungen und Möglichkeiten des Edge Computings zu erproben und zu demonstrieren.
Ziel ist die Entwicklung eines Mixed-SBC-Clusters für die Edge, der als experimentelle Plattform in industrienaher Forschung und für Lehrzwecke im Automatisierungsumfeld dient. Dieser Cluster soll die Heterogenität realer OT-Infrastrukturen bedienen und das Sammeln praktischer Erfahrungen mit Cluster-Management, verteilten Speichersystemen und der Integration von Erweiterungsmodulen (z.B. Funkmodul, Neural Processing Unit und Field Programmable Gate Array) eröffnen.
(Mögliche) Schwerpunkte der Arbeit:
- Aufbau und Konfiguration eines heterogenen SBC-Clusters für Edge Computing Szenarien.
- Einsatz eines Cluster-Management-Systems und Implementierung eines Service Mesh.
- Einsatz von Automatisierungswerkzeugen und Infrastruktur-as-Code (IaC) zur effizienten Verwaltung und Konfiguration.
- Implementierung eines Lifecycle-Managements des Betriebs bestehend aus Monitoring, Sicherung, Wartung und Aktualisierung.
- Integration von Storage-Lösungen und spezifischen Erweiterungsmodulen für verschiedene Anwendungsfälle.
- Integration in Anwendungsfälle der Automatisierungstechnik in industriellen Produktionsanlagen, der Gebäudeautomatisierung und insbesondere des Energiemanagements.
- Beitrag zum Transfer in die Lehre als Praktikumsversuch oder Übungseinheit
Wenn die ausgeschriebene Arbeit noch online ist, dann ist sie auch noch aktuell. Sollten Sie Interesse an der Arbeit haben, so kommen Sie bitte mittels einer E-Mail (in der Sie kurz Ihr Vorwissen darstellen) auf mich zu. Sollten Sie eine intrinsische Motivation für ein angrenzendes oder ähnlichen Thema haben, so stellen Sie in Ihrer Anfrage bitte den Bezug zu meiner Ausschreibung dar.
Bitte stellen Sie die komplette Anfrage in deutscher Sprache, auch wenn Sie die Ausarbeitung in Englisch verfassen werden. Hintergrund ist, dass Sie sich in laufende Forschungsprojekte einbringen mit den Unternehmen austauschen können sollen und von diesen wird mehrheitlich eine Kommunikation auf Deutsch gewünscht.
Weitere Informationen erhalten Sie auf Anfrage, der Arbeitsumfang kann entsprechend der Arbeit angepasst werden und die Bearbeitung weitestgehend im Home-Office stattfinden.
BA/PA: LLM-basierte Service-Automatisierung im Maschinenbau: Systematische Analyse der Prozessphasen klassicher Vorgehensmodelle
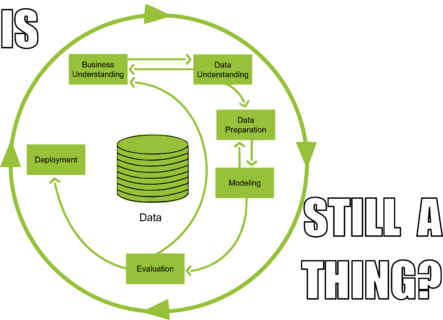
Kontext und Motivation
Service-Exzellenz ist einer der letzten verbleibenden Wettberwerbsvorteile deutscher Hidden Champions aus dem mittelständischen Maschinen- und Anlagenbau, um sich im Umfeld eines zunehmenden internationalen Preisdrucks zu behaupten. Doch der Fachkräftemangel einerseits und der drohende Wissensabfluss durch den bevorstehenden Renteneintritt maßgeblicher Service-Experten der Babyboomer-Generation andererseits gefährden diesen Vorsprung.
Generative KI verspricht hier Abhilfe zu schaffen: Durch die automatisierte Bearbeitung insbesondere einfacher technischer Kundenanfragen auf Basis des aktuell noch meist implizit vorliegenden Wissenschatzes der Unternehmen soll technischer Kundenservice durch Entlastung und gezielten Einsatz der verbleibenden Experten skalierbar gemacht werden.
Eine Herausforderung hierbei ist, dass etablierte Vorgehensmodelle für KI-Projekte wie etwa CRISP-DM aus einer Zeit von strukturierten Tabellendaten und prädiktiven Modellen stammen (Narrow AI). Es stellt sich daher die Frage in wie weit solch klassische Vorgehensmodelle für die Umsetzung LLM-basierter Anwendungen valide bleiben beziehungsweise welche Anpassungen für eine Erfolgreiche Umsetzung LLM-basierter Anwendungen nötig sind.
Ziel der Arbeit
Im Rahmen dieser Arbeit soll eine Systematic Literature Review (SLR) durchgeführt werden, um zu untersuchen, wie sich die Phasen des CRISP-DM-Modells für LLM-Projekte im industriellen Service-Kontext bereits verändert haben beziehungsweise verändern müssen.
Mögliche Schwerpunkte
Die Ausschreibung ist so konzipiert, dass verschiedene Studierende jeweils einzelne Phasen des CRISP-DM tiefgreifend analysieren können. Die Phasen des CRISP-DM:
- Business Understanding
- Data Understanding
- Data preparation
- Modeling
- Evaluation
- Deployment
Je nach Schwerpunkt der Arbeit werden initial zu unteruschende Forschungs- beziehungsweise Leitfragen definiert.
Aufgabeninhalte
- Durchführung einer strukturierten Literaturrecherche (z. B. via Scopus, Web of Science, IEEE Xplore).
- Identifikation von Anpassungsbedarfen des CRISP-DM-Modells für generative Wissensverarbeitung.
- Synthese der Ergebnisse: Welche Frameworks (z. B. FMDev, LLMOps) schlägt die Forschung als Nachfolger oder Ergänzung vor?
- Bezugnahme auf die spezifischen Herausforderungen im Maschinenbau beziehungsweise technischen Kundendienst (technische Komplexität, Sicherheit, Prompt Injection).
Vorkenntnisse
- Technischer Studiengang
- Idealerweise Vorkenntnisse bei der Durchführung von Literaturrechcherchen
- Interesse an Generativer KI, Knowledge Management und Prozessmodellen, idealerweise mit Vorkenntnis der technischen Hinterründe
- Strukturierte Arbeitsweise
- Gute Englisch-Kenntnisse für das Verständnis der Fachliteratur
Weitere Informationen auf Anfrage. Bewerbungen bitte per E-Mail mit aktueller Notenübersicht und Lebenslauf
[BA/PA/MA] Analyse, Konzeptentwicklung und Implementierung von Kommunikationsmechanismen zwischen Agenten in Multi-Agenten-Systemen
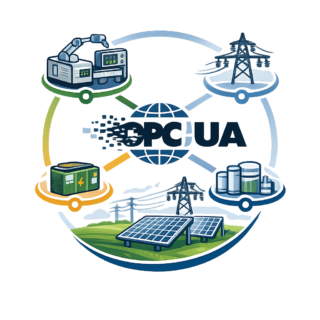
Ausgangssituation
Die DC-Fabrik gilt als Schlüsselkonzept zukünftiger energieeffizienter und hochflexibler Produktionssysteme. Durch die Elektrifizierung vieler Verbraucher, die Einbindung erneuerbarer Energien sowie den Einsatz von Energiespeichern entstehen komplexe Energiestrukturen, die dynamisch gesteuert werden müssen. Multi-Agenten-Systeme (MAS) bieten hierfür einen vielversprechenden Ansatz, indem sie autonome und verteilte Entscheidungen realisieren. Für einen stabilen und effizienten Betrieb benötigt ein MAS jedoch robuste Kommunikationsmechanismen, die standardisiert, skalierbar und echtzeitnah sind. OPC UA hat sich als zentraler Industriestandard etabliert und ermöglicht einheitliche, sichere und semantisch klare Kommunikation zwischen verteilten Einheiten – ideal für die Agentenkommunikation in einer DC-Fabrik.
Ziel der Arbeit
Ziel dieser Arbeit ist die Konzeption, Entwicklung und Evaluation eines Kommunikationskonzeptes für ein Multi-Agenten-System in der DC-Fabrik auf Basis von OPC UA. Der Fokus liegt auf der Modellierung von Agenteninteraktionen, der damit verbundenen Informationsmodelle und der simulativen bzw. prototypischen Umsetzung der Kommunikation.
Erwartungen an Studierende
- Strukturierte, selbstständige Arbeitsweise
- Erfahrung im wissenschaftlichen Arbeiten sowie in der Durchführung von Literaturrecherchen
- Gute Dokumentationsfähigkeit
- Fortgeschrittene Kenntnisse in Python
- Grundkenntnisse KI, Multi-Agentensystemen oder maschinellem Lernen
- Erfahrung mit OPC UA oder agentenbasierten Modellen
Bewerbung
Bewerbungen bitte mit Exposé, Lebenslauf und aktueller Fächerübersicht per E-Mail an Luca.Werthmann@faps.fau.de
[BA/PA/MA] Analyse globaler Finanzprodukte zur Förderung grüner Technologien: Eine systematische Literaturübersicht zur Identifikation von Hebeln und Finanzierungslücken für das 1,5-Grad-Ziel

Motivation & Hintergrund
Die Erreichung des globalen 1,5-Grad-Ziels des Pariser Klimaabkommens erfordert eine massive Transformation hin zu einer nachhaltigen Wirtschaft und die schnelle Skalierung grüner Technologien. Trotz des wachsenden Bewusstseins für Klimaschutz und Nachhaltigkeit ist die Finanzierung vieler klimapolitisch sinnvoller Innovationen und Projekte noch unzureichend. Es stellt sich die drängende Frage, welche Finanzierungsinstrumente bereits existieren, wo deren Grenzen liegen und warum nicht alle notwendigen grünen Technologien im erforderlichen Umfang finanziert werden. Der Finanzsektor spielt hierbei eine entscheidende Rolle als Katalysator oder Hemmschuh für den Übergang zu einer kohlenstoffarmen Zukunft.
Diese Masterarbeit entsteht in Kooperation mit einem Unternehmen, das ein tiefes Interesse daran hat, die Landschaft der grünen Finanzierung zu verstehen, um eigene Strategien und Investitionsentscheidungen zu optimieren. Die Arbeit wird als selbstständige, wissenschaftliche Literaturrecherche durchgeführt und bietet die Möglichkeit, einen kritischen Beitrag zur aktuellen Debatte um Klimafinanzierung zu leisten.
Das Thema ist für Masterstudierende von hoher Relevanz und anspruchsvoll. Es verlangt nicht nur ein fundiertes Verständnis der Finanzmärkte und ihrer Produkte, sondern auch ein kritisches Urteilsvermögen bezüglich deren Effektivität im Kontext globaler Klimaziele. Die systematische Anwendung einer etablierten Forschungsmethodik wie PRISMA sowie die Fähigkeit, komplexe Zusammenhänge zwischen Finanzinnovationen und Klimaschutz darzustellen, machen diese Arbeit zu einer wertvollen akademischen und praktischen Herausforderung.
Ziel der Arbeit
Das übergeordnete Ziel dieser Masterarbeit ist die systematische Identifikation, Kategorisierung und kritische Bewertung globaler Finanzprodukte, die zur Finanzierung grüner Technologien eingesetzt werden.
Mithilfe einer umfassenden Literaturrecherche nach der PRISMA-Methode sollen die charakteristischen Merkmale, Anwendungsbereiche und Wirkungsweisen dieser Finanzinstrumente herausgearbeitet werden. Ein zentrales Anliegen ist es, die konkreten Hebel zu identifizieren, die diese Produkte zur Förderung grüner Technologien nutzen, sowie die bestehenden Limitationen und Finanzierungslücken aufzuzeigen, die der Erreichung des 1,5-Grad-Ziels entgegenstehen. Die Arbeit soll somit eine fundierte Basis für die Entwicklung zukünftiger Strategien zur effektiveren Klimafinanzierung schaffen.
Der Fokus der Arbeit liegt primär auf der Methodenentwicklung (systematische Anwendung der PRISMA-Methode) und der empirischen Analyse der identifizierten Finanzprodukte und ihrer Charakteristika, ergänzt durch eine kritische Bewertung ihrer Wirksamkeit.
Aufgabenstellung
Die Masterarbeit umfasst folgende Hauptaufgabenblöcke:
- Konzeption der systematischen Literaturrecherche nach PRISMA o.Ä.:
- Definition der Forschungsfrage(n) und relevanter Schlüsselbegriffe für die Literaturrecherche.
- Entwicklung eines detaillierten Suchprotokolls gemäß der PRISMA-Methodik, einschließlich der Auswahl geeigneter wissenschaftlicher Datenbanken (z.B. Web of Science, Scopus, Google Scholar, sowie ggf. spezifische Finanzdatenbanken wie Bloomberg Terminal oder Refinitiv Eikon).
- Festlegung von Ein- und Ausschlusskriterien für die zu analysierenden Publikationen und Finanzprodukte.
- Durchführung der systematischen Literaturrecherche und Datenerhebung:
- Systematische Durchführung der Literaturrecherche anhand des entwickelten Suchprotokolls (Identifikation, Screening, Prüfung der Eignung).
- Extraktion relevanter Informationen aus den identifizierten Publikationen, um die Finanzprodukte für grüne Technologien detailliert zu beschreiben. Dies umfasst: Art des Finanzprodukts, Zieltechnologien, geografischer Fokus, Volumen, beteiligte Akteure, Wirkungsmechanismen, identifizierte Erfolgsfaktoren und Herausforderungen.
- Dokumentation des gesamten Prozesses, inklusive der Anzahl der identifizierten, gescreenten und eingeschlossenen Artikel, gemäß PRISMA-Flow-Diagramm.
- Analyse und Kategorisierung der Finanzprodukte:
- Kategorisierung der identifizierten Finanzprodukte basierend auf ihren Charakteristika, Wirkungsweisen und Zielsetzungen (z.B. nach Art der Finanzierung, Risikoprofil, Sektorbezug).
- Detaillierte Ausarbeitung, worin sich die Produkte unterscheiden, ergänzen oder ähneln.
- Identifikation der konkreten “Hebel”, die diese Finanzprodukte nutzen, um die Entwicklung und Skalierung grüner Technologien zu fördern (z.B. Risikoteilung, Anreize, Kapitalmobilisierung).
- Analyse des globalen Marktes und regionaler Besonderheiten, auch wenn viele Fonds regional beschränkt sind.
- Kritische Bewertung und Identifikation von Finanzierungslücken:
- Kritische Bewertung der Effektivität und Reichweite der identifizierten Finanzprodukte im Hinblick auf die Erreichung des 1,5-Grad-Ziels.
- Identifikation von Bereichen, in denen die aktuelle Finanzierungslandschaft Lücken aufweist oder unzureichend ist, um klimapolitisch sinnvolle Technologien im erforderlichen Maße zu finanzieren.
- Analyse der Ursachen für diese Lücken (z.B. Marktversagen, regulatorische Hürden, Wahrnehmung von Risiken, fehlende Anreize).
- Ableitung von Handlungsempfehlungen:
- Formulierung von fundierten Handlungsempfehlungen für Unternehmen, Investoren, politische Entscheidungsträger und Technologieentwickler, um die Finanzierung grüner Technologien zu optimieren und bestehende Lücken zu schließen.
- Vorschläge für die Weiterentwicklung bestehender oder die Schaffung neuer Finanzinstrumente.
Erwarteter Output
Die Masterarbeit soll folgende Ergebnisse liefern:
- Schriftliche Masterarbeit: Eine wissenschaftliche Ausarbeitung, die die Motivation, die detaillierte Methodik (PRISMA-Protokoll und -Durchführung), die Analyse der Finanzprodukte, die kritische Bewertung und die abgeleiteten Handlungsempfehlungen darlegt.
- PRISMA-Flow-Diagramm: Eine grafische Darstellung des Rechercheprozesses.
- Strukturierte Datenbank/Übersicht: Eine detaillierte und kategorisierte Übersicht der identifizierten Finanzprodukte (z.B. in Excel oder einem vergleichbaren Format), die deren wesentliche Merkmale und Wirkungsweisen zusammenfasst.
- Visualisierungen: Klare und aussagekräftige grafische Darstellungen der Ergebnisse (z.B. tabellarische Übersichten, vergleichende Matrizen, Flussdiagramme von Finanzierungsströmen oder Netzwerkdiagramme), die die Vielfalt, Überschneidungen und Lücken der Finanzprodukte illustrieren. Hierfür können gängige Tools wie Excel, PowerPoint oder bei Bedarf Python/R-Bibliotheken genutzt werden.
- Praxisempfehlungen: Konkrete und umsetzbare Empfehlungen zur Verbesserung der Finanzierung grüner Technologien.
Zielgruppe & Anforderungen
Diese Masterarbeit richtet sich an engagierte Studierende der folgenden Studiengänge:
- Wirtschaftswissenschaften
- Wirtschaftsingenieurwesen
- MBA-Programme
- oder verwandte Studienrichtungen mit wirtschaftlichem Fokus
Erforderliche Kenntnisse und Fähigkeiten:
- Ausgeprägte analytische Fähigkeiten und ein kritisches Urteilsvermögen.
- Erfahrung mit wissenschaftlichen Datenbanken (z.B. Web of Science, Scopus) und idealerweise Kenntnisse im Umgang mit Finanzdatenbanken (z.B. Bloomberg Terminal, Refinitiv Eikon) oder die Bereitschaft, sich diese anzueignen.
- Kenntnisse in Literaturverwaltungssoftware (z.B. Citavi, EndNote, Zotero) sind von Vorteil.
- Interesse an Finanzmärkten, grünen Technologien, Klimaschutz und datenbasierter Entscheidungsunterstützung.
Soft Skills:
- Analytisches Denkvermögen und Problemlösungskompetenz.
- Selbstständige, strukturierte Arbeitsweise und hohe Eigeninitiative.
- Exzellente Kommunikationsfähigkeiten in Wort und Schrift (für die wissenschaftliche Ausarbeitung und Präsentation).
- Sehr gute Deutsch- und gute Englischkenntnisse in Wort und Schrift.
Rahmenbedingungen
- Dauer: Die Bearbeitungszeit für die Masterarbeit beträgt 6 Monate.
- Beginn: Der Beginn der Arbeit ist nach Absprache flexibel gestaltbar.
- Betreuung: Die Studierenden erhalten eine enge und fachkundige Betreuung durch erfahrene Forschende.
- Projektkontext: Die Arbeit ist in einen aktuellen, praxisnahen Forschungskontext mit industriellem Anwendungsbezug eingebunden.
- Ressourcen: Notwendige Hardware- und Software-Ressourcen entsprechen den gängigen Lösungen der Universität, einschließlich Zugang zu wissenschaftlichen Datenbanken und Standardsoftware für Datenanalyse und Textverarbeitung.
Arbeitsweise: Die Arbeitsweise kann flexibel gestaltet werden (Hybrid-Modell oder Remote-Arbeit nach Absprache), wobei regelmäßige Abstimmungen und der Austausch mit dem Betreuungsteam sichergestellt sind.
[PT/MT] Geo-Modeling and Assessment of Global Production Networks

Background
Modern production and supply networks span multiple continents, combining various transport modes (road, sea, rail, air). Understanding the geographical structure, costs, and environmental impacts of these logistics routes is key to designing resilient and sustainable global value chains. This thesis contributes to a research project on modeling and optimizing international production networks. The focus lies on geo-spatial modeling of transport flows, calculation of transport costs and emissions, and interactive visualization of global supply routes.
Objectives
Develop a geo-based Python model that:
- Maps realistic transport routes between global production and assembly sites,
- Calculates transport distances, costs, and CO₂ emissions based on real data,
- Visualizes results interactively on a world map (e.g., using folium or geopandas).
Main Tasks
Data Collection and Preparation
- Identify suitable open geospatial datasets (e.g., Global Shipping Lanes, OpenStreetMap).
- Gather emission and transport cost factors (e.g., from the GLEC Framework).
Model Development
- Implement routing and distance calculations for combined transport modes.
- Compute costs and CO₂ emissions for selected routes or network scenarios.
Visualization and Analysis
- Create an interactive geo-visualization of the modeled network.
- Document assumptions, data sources, and main findings.
Requirements
- Ongoing studies at FAU
- Good programming skills in Python
- Experience with data analysis and mapping tools (pandas, geopandas, folium) preferred
- Interest in global production networks, sustainability, and data-driven modeling
Tools / Frameworks
- Python (pandas, geopandas, folium, shapely)
- Open geospatial data (OpenStreetMap, Global Shipping Lanes, etc.)
- Emission frameworks such as GLEC Framework
Type of Thesis
- Final Thesis (Bachelor / Master)
- Type: Theoretical thesis / Systematic literature review
- Start date: flexible
Please send your complete application documents (short cover letter, work/internship certificates, and current transcript of records) to: baris.albayrak@faps.fau.de
I look forward to hearing from you!
[MA] Datenbasierte Früherkennung externer Schocks in industriellen Wertschöpfungsnetzwerken

Ausgangssituation
Produzierende Unternehmen sehen sich zunehmend externen Schocks ausgesetzt, etwa durch geopolitische Ereignisse, Naturereignisse, Marktveränderungen oder externe IT-Störungen. Diese beeinflussen Lieferketten und Produktionsprozesse oft unmittelbar, sind jedoch in vielen Fällen bereits frühzeitig in Daten erkennbar. Ein systematisches, interorganisationales Frühwarnkonzept ist in der Praxis jedoch selten vorhanden.
Aufgabenstellung
Ziel der Arbeit ist die Entwicklung eines Risikofrühwarn-Frameworks, das Unternehmen bei der Erkennung und Bewertung externer Schocks unterstützt. Ergänzend soll ein Python-basierter Prototyp entstehen, der anhand von Dummy- oder Open-Data zentrale Frühindikatoren visualisiert und eine interaktive Entscheidungsunterstützung ermöglicht.
Die Arbeit gliedert sich grob wie folgt:
- Analyse bestehender Ansätze zu externen Schocks, Supply-Chain-Risiken und relevanten Datenquellen.
- Kategorisierung externer Schockarten und Identifikation typischer Frühindikatoren.
- Entwicklung eines interorganisationalen Risikofrühwarn-Frameworks mit klaren Rollen, Prozessen und Datenflüssen.
- Entwicklung eines Python-Dashboards (Decision-Support) zur Visualisierung und Szenarienanalyse.
- Demonstration und Evaluation anhand ausgewählter Beispielschocks.
Vorkenntnisse/Voraussetzungen:
- Interesse an Risiko-, Lieferketten- oder Produktionsmanagement
- Fähigkeit zu wissenschaftlicher Analyse und Modellbildung
- Grundkenntnisse in Python (Datenanalyse / Visualisierung)
- Strukturierte und selbstständige Arbeitsweise
Tools / Frameworks:
Python, Jupyter Notebook oder VS Code; optional Process-Mining- oder ML-Bibliotheken.
Methodischer Rahmen: Design Science Research
Type of Thesis:
Masterarbeit (ca. 6 Monate)
Framework-Entwicklung mit prototypischer Umsetzung.
Studiengänge:
Wirtschaftsingenieurwesen, Maschinenbau, Wirtschaftsinformatik, Informatik, Data Science, Artificial Intelligence, Mechatronik.
Bewerbung:
Die Arbeit kann ab sofort bearbeitet werden. Bewerbungen bitte per Mail mit Lebenslauf und aktuellem Notenauszug an untenstehenden Kontakt, Adrian Müller mit Baris Albayrak in CC, richten.
[BA/PA/MA] Entwicklung eines semantischen Capability-Modells zur resilienten Produktionsorchestrierung
Ausgangssituation:
In einer von raschem Wandel und technologischer Turbulenz geprägten Welt müssen sich Unternehmen flexibel an veränderte Umstände anpassen.
Dabei spielen resiliente Produktionsabläufe und -systeme eine entscheidende Rolle. Neben der Neuplanung (Greenfield) von Produktionslinien
stellt insbesondere die Umstrukturierung bestehender Anlagen (Brownfield) eine Herausforderung dar. Dabei müssen jeweils die Möglichkeiten zur Flexibilisierung berücksichtigt werden, um ein
notwendiges Maß an Anpassungsfähigkeit sicherzustellen.
Aufgabenstellung:
In dieser Arbeit soll ein Konzept für ein Capability-Modell zur resilienten Produktionsorchestrierung erarbeitet und modelliert werden, um eine Flexibilisierung von Produktionslinien zu vereinfachen.
Die Arbeit gliedert sich grob wie folgt:
- Einarbeitung in den Stand der Technik
- Erarbeitung der wichtigsten Teile der Produktion,
- Konzeptionierung des Capability-Modells
- Modellierung in z. B. JSON.
- Beispielhafte Anwendung in einem Orchestrierungsszenario.
- Schriftliche Dokumentation der Ergebnisse
Vorkenntnisse/Voraussetzungen:
- Interesse an industrieller Fertigung und Automatisierung.
- Selbstständige und strukturierte Arbeitsweise.
- Gute Dokumentationsfähigkeiten
- Gute Kenntnisse der deutschen oder englischen Sprache
Weitere Hinweise:
- Startdatum: ab sofort möglich
- Homeoffice möglich
Bewerbung:
Bewerbungen bitte mit Lebenslauf, aktueller Fächerübersicht und arbeitsprobe (JSON/XML-File) per E-Mail an: adrian.mueller@faps.fau.de.
Das JSON oder XML-File soll folgende Informationen strukturiert beinhaltet:
- Der Name des Files soll sich aus der Arbeit (BA,PA oder MA) + “_” + deinem Nachnamen zusammensetzten
- Das File soll selbstgeschrieben sein
- Vorname, Nachname, Geburtstag, Geburtsort, Wohnort, besuchte Bildungseinrichtungen, mindestens fünf besuchte Fächer mit Note pro Bildungseinrichtung und alle Sprachen mit Level.
Für weitere Informationen über den Umfang und die genaue Ausrichtung der Arbeit stehe ich gerne für ein persönliches Gespräch zur Verfügung.
[BA/PA/MA] Potentialalyse zum Gleichstrombetrieb einer Wellpappenanlage

Anlagen zur Herstellung von Wellpappe verfügen über eine Vielzahl von drehzahlsynchronisierten elektrischen Antrieben.
Im Stand der Technik erfolgt die Energieversorgung und Ansteuerung über Umrichter, welche Energie aus dem Wechselstromnetz beziehen und überschüssige Energie in Bremswiderständen in Wärme umwandeln.
Durch die Umstellung auf Gleichstrom (DC) in Produktionsanlagen können erhebliche Vorteile erzielt werden, insbesondere in Bezug auf Energieeffizienz, Materialersparnis und Systemstabilität. DC-basierte Systeme ermöglichen eine flexiblere Energienutzung, höhere Wirkungsgrade und ermöglichen die Rückspeisung vom Bremsenergie (Rekuperation).
Ziel der Arbeit:
Im Rahmen der Arbeit sollen die Energie- und Materialeinsparpotenziale durch den Einsatz eines DC-Netzes mit zentralem DC-Bus zur Versorgung der drehzahlvariablen Antriebe einer Maschine zur Herstellung von Wellpappe evaluiert werden. Die Möglichkeit zur Nutzung von Bremsenergie durch Rekuperation soll geprüft werden.
Arbeitspakete:
- Analyse des Ist-Zustands: Besichtigung einer Anlage beim Industriepartner und sammeln der nötigen Daten aus den Technischen Dokumentationen, Einführung in den DC-Demonstrator am FAPS, Einlesen in die Fachliteratur
- Konzeption einer DC-Maschine: Auswahl geeigneter DC-fähiger Umrichter, Auslegung des DC-Netzes; Analyse der Lastprofile der Motoren zur Evaluation des Einsatzes von Rekuperation
- Bewertung der Einsparpotenziale: Quantifizierung der Energiesparpotenziale auf Basis von Literatur oder eigener Laborversuche, Identifikation und Quantifizierung der Materialeinsparpotenziale
Anforderungen:
- Kenntnisse in Elektrotechnik, idealerweise mit Bezug zur DC-Technologie und Energieeffizienz in Produktionsumgebungen von Vorteil
- Selbstständige und strukturierte Arbeitsweise
- Gute Deutsch- und Englischkenntnisse in Wort und Schrift
[BA/PA/MA] Adaptive Agentensysteme: Struktur, Lernen und Kommunikation in dynamischen Umgebungen

Hintergrund:
In der Entwicklung intelligenter Produktions- und Logistiksysteme nehmen autonome, vernetzte Agenten eine Schlüsselrolle ein. Um komplexe Aufgaben effizient zu bewältigen, müssen diese Systeme nicht nur lernen, sondern auch ihre interne Struktur und Kommunikation dynamisch anpassen können. Ziel dieser Arbeit ist es, in einer simulativen Testumgebung verschiedene Konzepte für Agentenarchitektur, Lernen und Interaktion zu erforschen und methodisch zu evaluieren.
Ziel der Arbeit:
Entwicklung und Analyse eines simulationsbasierten Multi-Agenten-Systems mit einem von drei Schwerpunkten:
Themenoption 1: Atomare Agentenstrukturen & Rollenverteilung mit Fokus auf Architektur und Organisation
- Modellierung von Agenten als “Atome” mit vernetzbaren Rollen (z. B. Spezialist, Manager)
- Dynamische Bildung von Systemstrukturen über agentenbasierte Verknüpfungslogik
- Aufbau und Visualisierung eines Agentennetzwerks
- Konzeption einer “Agentenbörse” zur strukturierten Verknüpfung
Themenoption 2: Meta-Learning im Reinforcement Learning mit Fokus auf Lernen & Adaption
- Vergleich klassischer RL-Methoden mit Meta-Learning-Ansätzen (z. B. MAML, Reptile)
- Simulation eines adaptiven Agenten in einer rudimentären Umgebung (x, y, dx, dy)
- Bewertung der Anpassungsfähigkeit in dynamischen Zielsystemen
- Analyse von Vor- und Nachteilen des Meta-Learnings
Themenoption 3: Spieltheorie in Multi-Agenten-Kommunikation mit Fokus auf Kooperation & Täuschung
- Interaktion durch „Horizont“/Ziel-Überschneidungen und Kommunikation zwischen Agenten
- Modellierung von Täuschern und Strategien zur Erkennung
- Integration spieltheoretischer Konzepte wie Vertrauen, Betrug, Kooperation
- Aufbau eines agentenbasierten Kommunikations- und Bewertungssystems
Vorgehensweise:
- Einarbeitung in Multi-Agenten-Systeme und Reinforcement Learning
- Auswahl und Ausarbeitung eines der drei Schwerpunktbereiche
- Aufbau eines simulativen Testsystems (z. B. mit Python)
- Implementierung und Evaluation der entwickelten Ansätze
- Dokumentation und Diskussion der Ergebnisse
Anforderungen an Studierende:
- Strukturierte, selbstständige Arbeitsweise
- Erfahrung im wissenschaftlichen Arbeiten sowie in der Durchführung von Literaturrecherchen
- Gute Dokumentationsfähigkeit
- Fortgeschrittene Kenntnisse in Python
- Grundkenntnisse KI, Multi-Agentensystemen oder maschinellem Lernen
Bewerbung:
Bewerbungen bitte mit Lebenslauf und aktueller Fächerübersicht per E-Mail an Luca.Werthmann@faps.fau.de