Index
[MA] Simulation einer Automatisierung zur Blechverarbeitung im Transformatorenbau

Siemens Energy bietet aktuell eine Masterarbeit zur Analyse und Simulation einer Automatisierungslösung für die Blechbearbeitung zur Optimierung von Prozessen und Qualität an. Die Arbeit wird im Werk für Großtransformatoren in Nürnberg durchgeführt. Weitere Informationen unter:
https://jobs.siemens-energy.com/en_US/jobs/FolderDetail/292057
Intelligente Prozessoptimierung beim Richten von Flachdraht für elektrische Antriebe [BA/PA/MA]

Hintergrund
Die Fertigung elektrischer Antriebe, wie etwa Hairpin-, Continuous-Hairpin- oder Axialflussmaschinen, erfordert eine präzise Kontrolle von Material und Prozess. Ein zentraler Schritt ist das Richten von Flachdraht, das bislang auf festen Parametern und Erfahrungswissen basiert. Dabei werden Schwankungen im Material nur unzureichend berücksichtigt. Das Ziel besteht darin, diesen Prozess mithilfe moderner Sensorik, Messtechnik und innovativer Regelungsansätze weiterzuentwickeln, um die Produktionsqualität effizient zu steigern.
Mögliche Aufgabenstellungen
Studentische Arbeiten können zu einem der folgenden Themen erarbeitet werden:
- Integration eines Interferometers zur Isolationsschichtdickenmessung
- Integration von Sensorik zur Überwachung der Abhaspeleinrichtung
- Erweiterung der prototypischen Versuchsanlage um Sicherheitstechnik
- Modellierung und Simulation des Richtprozesses
- Weiterentwicklung einer flexiblen, mechanischen Abisolierstation für Flachdraht
- SPS-Programmierung einer Schwenkbiege-Anlage zum 2D-Biegen von Flachdraht
Die detaillierten Inhalte und Aufgabenstellungen werden in einem persönlichen Gespräch besprochen.
Anforderungsprofil
- Interesse an der Produktion elektrischer Traktionsantriebe
- Je nach Themengebiet sind Grundkenntnisse in Konstruktion, Messtechnik, Programmierung, Datenanalyse (KI/ML) oder Regelungstechnik erforderlich.
- Freude an praktischer Arbeit (Versuchsreihen, Messtechnik, Anlagenaufbau)
- Analytisches, strukturiertes und selbstständiges Arbeiten
- Teamfähigkeit und Kommunikationsstärke
- Gute Deutsch- und Englischkenntnisse in Wort und Schrift
Bewerbung
Bitte senden Sie Ihre Bewerbung mit
- Lebenslauf
- Aktuellem Notenspiegel
- Angabe der bevorzugten Aufgabenstellung
per E-Mail an anja.preitschaft@faps.fau.de
Wichtig: Bewerbungen ohne konkrete Nennung eines Themenbereichs können leider nicht bearbeitet werden.
MA/PA: Simulation of Microexpressions for Human-Robot Interaction

We are looking for curious and motivated master’s students to join an innovative research project on the simulation of microexpressions in virtual human faces for humanoid robotics and human-robot interaction. This thesis combines social robotics, facial expression modeling, computer animation, and user-centered evaluation, contributing to the development of more expressive and socially intelligent virtual agents.
Project Overview:
This master’s thesis focuses on the simulation and evaluation of human microexpressions in virtual faces and computer-based environments. Microexpressions are subtle and short facial movements that play an important role in social communication. The aim of this thesis is to investigate how such expressions can be modeled, implemented, and perceived in virtual humans or simulated humanoid agents.
Possible research directions include:
- Study of the physiological and expressive basis of human microexpressions
- Investigation of methods for modeling subtle facial expressions in virtual agents
- Simulation of microexpressions using animation and facial modeling tools such as Blender, Unity, Unreal Engine / MetaHuman, or related frameworks
- Exploration of facial action units, blendshapes, or similar techniques for implementing subtle facial movements
- Evaluation of user preferences and perception regarding realism, naturalness, and social acceptability
The thesis will help establish a foundation for future emotionally expressive virtual humans and humanoid robots by identifying suitable design approaches and perception-related challenges.
Key Responsibilities:
- Conduct a structured review of literature on microexpressions, facial expression modeling, and human-robot interaction
- Investigate existing methods and tools for simulating subtle facial expressions in virtual environments
- Implement or prototype selected microexpression simulation approaches in a computer-based setting
- Design and analyze a user study to evaluate perceived realism, preference, and social impact
Who We’re Looking For:
- Strong interest in social robotics, virtual humans, humanoid robots, human expression, or human-robot interaction
- Background in robotics, biomedical engineering, computer science, HRI, computer graphics, animation, or a related field
- Interest in simulation, experimental design, and user-centered evaluation
- Independent, structured, and critical way of working
- Fluency in English
How to Apply:
If you are excited about expressive virtual humans and would like to contribute to research on artificial facial behavior, we invite you to apply exclusively via email, including your CV and complete transcript of records (GPA min. 2.5).
Subject: S2.1_Virtual Microexpressions
[BA/PA/MA] AI-gestützte Erkennung elektrischer Prüfpunkte in Schaltschränken

Motivation
Im Rahmen des Forschungsprojekts „ProTekt“ am FAPS arbeiten wir an der Automatisierung der Qualitätsprüfung von Schaltschränken. Ein wichtiger Baustein dabei ist die elektrische Prüfung. Damit ein Roboter elektrische Messungen automatisiert durchführen kann, müssen die passenden Prüfpunkte an den verbauten Komponenten zuverlässig erkannt und lokalisiert werden. Prüfpunkte sind die elektrischen Kontaktstellen an den Komponenten, über die einzelne Anschlüsse elektrisch ankontaktiert werden können. In der Praxis ist ihre Erkennung jedoch herausfordernd: Form, Lage, Größe und visuelle Erscheinung variieren stark zwischen unterschiedlichen Herstellern, Komponentenarten und Schaltschrankaufbauten.
Ziel der Arbeit
Ziel deiner Arbeit ist es, ein leichtgewichtiges Computer-Vision-Verfahren zur robusten Erkennung von Prüfpunkten zu entwickeln, zu bewerten und prototypisch umzusetzen. Im Zentrum steht dabei ein CNN-basiertes Modell, das Prüfpunkte als eigene Objektklasse erkennt und auch bei hoher Varianz der Komponenten zuverlässig funktioniert.
Dazu gehört insbesondere:
- Einarbeitung in den Projektkontext und die Rolle elektrischer Prüfpunkte in der automatisierten Schaltschrankprüfung
- Analyse vorhandener Bilddaten sowie Einbezug und Bewertung geeigneter Online-Datensätze für Training und Validierung
- Optional: Anpassung einer bestehenden Pipeline zur Erzeugung synthetischer Daten, sodass diese auch für Prüfpunkte genutzt werden kann
- Entwicklung eines leichtgewichtigen CNN-basierten Ansatzes zur Detektion
- Untersuchung, welche Merkmale und Datenrepräsentationen für eine robuste Generalisierung über viele Komponenten hinweg geeignet sind
- Entwicklung einer geeigneten Methodik, um die Robustheit des Systems bei hoher Varianz nachvollziehbar nachzuweisen
- Durchführung einer sinnvollen Evaluierung mit unterschiedlichen Komponentenklassen, Ausprägungen und Schwierigkeitsgraden
Ziel ist ein Prüfpunkt-Detektionssystem, das nicht nur auf wenigen Einzelbeispielen funktioniert, sondern seine Robustheit auch über eine große Bandbreite realer Komponenten hinweg nachvollziehbar zeigt.
Anforderungen an den Studierenden
- Studium im Bereich Maschinenbau, Mechatronik, Wirtschaftsingenieurwesen oder vergleichbar
- Interesse an Computer Vision, Deep Learning und praxisnaher AI-Anwendung
- Erste Programmierkenntnisse, vorzugsweise in Python
- Selbstständige und strukturierte Arbeitsweise
- Sehr gute Deutsch oder Englisch Kenntnisse
Bewerbungen bitte per Mail mit Lebenslauf und aktuellem Notenspiegel an matthias.lang@faps.fau.de
Start: jederzeit möglich
Ort: Nürnberg am FAPS Standort „auf AEG“ – hybrid möglich
[BA\PA\MA]: Event- and Frame-Based Vision for Wire Tracking
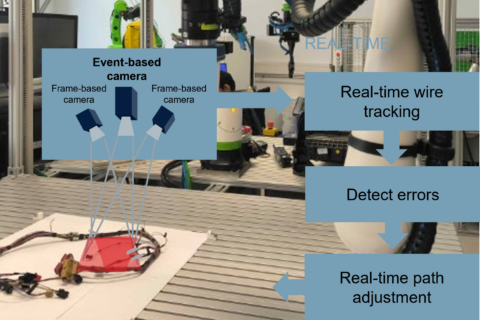
Initial Situation:
The handling and processing of cables and wires is currently characterized by manual activities due to their flexible material behavior. However, due to the ever-increasing complexity of cable systems in vehicle construction, there is also an acute need for action in industry to automate the process. As part of an automation project with a major German OEM, an automation solution is to be developed for cable harness production and assembly in the vehicle.
Possible thesis:
The objective of this thesis is to optimize existing computer vision algorithms for the robotic insertion of a wiring harness into the center console of a contemporary premium vehicle. The scope is roughly divided as follows and can be tailored according to your interests:
- Designing a comparative framework for benchmarking event-based vision algorithms against traditional frame-based methods
- Investigate potential of a multimodal fusion approach integrating event- and frame-based vision with force / acoustic sensing for enhanced process feedback
- Implementing & testing the system in a simulated or experimental setup involving robotic insertion and inspection tasks
- Analyzing performance metrics such as latency, accuracy, and robustness under varying conditions
- Discussion and outlook on further development possibilities
Focus on:
- 3D Computer Vision
- Pose estimation
- Robotics
What you should bring:
- Independent and structured work style
- Good documentation of the approach
- Good knowledge of German or English language
- Python knowledge desirable
- Computer Vision knowledge advantageous
Other notes:
- Start date can be immediate
- Remote work possible
- Work scope can be individually tailored according to interests
- Please apply with a current grade transcript and resume
[BA\PA\MA]: Real-time Path Adjustment of Industrial Robots in ROS2 for Obstacle Avoidance

Initial Situation:
The handling and processing of cables and wires is currently characterized by manual activities due to their flexible material behavior. However, due to the ever-increasing complexity of cable systems in vehicle construction, there is also an acute need for action in industry to automate the process. As part of an automation project with a major German OEM, an automation solution is to be developed for cable harness production and assembly in the vehicle.
Scope of the thesis:
The objective of this thesis is to implement methods for real-time path adjustment based on in order to grasp a wire harness and avoid entanglement of the wires. Several approaches (e.g. Reinforcement Learning, Learning-by-Demonstration and Sim2Real with Nividia Isaac Sim) should be tested and compared. The thesis is roughly divided as follows:
- Familiarization with ROS2 and programming of industrial robots
- Adaptation of the simulation environment and training of agents
- Improvement of algorithms to generate the parameters for position correction
- Transfer and validation on real systems
Benefits
- Hands-on experience in robotics development
- Exchange with other students at FAPS
- Insights into other areas of research
- Application-oriented work for career entry
What you should bring:
- Interest in AI-supported robotics and learning systems
- Experience in programming with Python/C++ and ROS2, as well as basic knowledge of machine learning
- Independent, structured, and scientifically sound approach to work
- German (C1) or English (C1)
Other notes:
- Start date can be immediate
- Remote work possible
- Work scope can be individually tailored according to interests
- Please apply with a current grade transcript and resume
[BA/PA/MA] Branchenanalyse des Schaltschrankbaus mit Fokus auf Prüfprozesse und Automatisierungspotenziale
Motivation
Der Schaltschrankbau ist eine zentrale, aber wenig standardisierte Industriebranche mit hoher Varianz in Produkten, Anwendungen und Fertigungsprozessen. Gleichzeitig steigen die Anforderungen an Qualität, Dokumentation und Effizienz. Die Prüfung von Schaltschränken ist dabei ein kritischer Schritt, der heute noch stark manuell geprägt ist. Im Rahmen des Projekts „ProTekt“ am FAPS wird die Automatisierung dieser Prüfprozesse gezielt erforscht und weiterentwickelt.
Ziel der Arbeit
Ziel der Arbeit ist es, eine strukturierte Branchenübersicht des Schaltschrankbaus zu erarbeiten und daraus die Anforderungen, bestehende Lösungen sowie Potenziale für die Automatisierung der Qualitätsprüfung systematisch abzuleiten.
Dazu gehört insbesondere:
- Strukturierung der Branche anhand relevanter Dimensionen (z.B. Arten von Schaltschränken, Spannungsebenen und Leistungsbereiche, Einsatzbranchen, …)
- Analyse typischer Fertigungs- und Montageprozesse im Schaltschrankbau
- Untersuchung relevanter Normen und Richtlinien für die Prüfung (z. B. elektrische, visuelle und funktionale Prüfungen)
- Überblick über bestehende kommerzielle Prüflösungen, sowie Automatisierungslösungen mit Einfluss auf die Prüfung
- Systematische Ableitung von Anforderungen und Herausforderungen für die Prüfautomatisierung
- Identifikation von Dimensionen, die die Relevanz und das Potenzial von Automatisierung beeinflussen (z. B. Varianz, Stückzahlen, Komplexität, Sicherheitsanforderungen)
- Erarbeiten offener Fragen, die im Rahmen einer späteren Branchenumfrage adressiert werden können
Ziel ist ein klar strukturiertes Gesamtbild der Branche mit einem besonderen Augenmerk auf Qualitätsprüfung, das als Grundlage für weitere Forschungs- und Entwicklungsarbeiten dient.
Anforderungen an den Studierenden
- Studium im Bereich Maschinenbau, Mechatronik, Wirtschaftsingenieurwesen oder vergleichbar
- Interesse an industriellen Prozessen und technischen Systemen
- Fähigkeit, komplexe Themen strukturiert zu analysieren und aufzubereiten
- Selbstständige Literatur- und Internetrecherche
Bewerbungen bitte per Mail mit Lebenslauf und aktuellem Notenspiegel and matthias.lang@faps.fau.de
Start: jederzeit möglich
Ort: Nürnberg am FAPS Standort „auf AEG”
Die Durchführung der Arbeit ist remote möglich
BA/PA/MA: Simulation sehnengetriebener Robotersysteme in Isaac Sim

Motivation
Sehnengetriebene Aktuationssysteme sind ein zentraler Ansatz moderner Robotik, insbesondere für humanoide und leichte, energieeffiziente Systeme. Durch die Entkopplung von Aktuator und bewegter Struktur lassen sich Massen reduzieren und komplexe Bewegungen realisieren. Für Entwicklung, Auslegung und spätere Steuerung solcher Systeme sind realitätsnahe Simulationen essenziell.
Unterschiedliche physikalische Modellierungsansätze für Seil- und Sehnenstrukturen (z. B. vereinfachte oder kontinuierliche Modelle) unterscheiden sich jedoch stark hinsichtlich Genauigkeit, Stabilität und Rechenaufwand. Diese Unterschiede wirken sich direkt auf die Nutzbarkeit in simulationsbasierten Entwicklungsprozessen und insbesondere auf Reinforcement-Learning-Anwendungen in NVIDIA Isaac Sim / Isaac Lab aus.
Ziel der Arbeit
Ziel der Arbeit ist die systematische Untersuchung und prototypische Implementierung ausgewählter Simulationsmethoden für Seil- und Sehnenstrukturen. Im Fokus steht die Frage, wie unterschiedliche physikalische Modellierungen praktisch umgesetzt werden können und welchen Einfluss sie auf das Verhalten der Simulation sowie auf die Trainingsstabilität und Performance von RL-Algorithmen haben.
Die Ergebnisse sollen vergleichbar aufbereitet und hinsichtlich ihrer Eignung für robotische Anwendungen bewertet werden.
Schwerpunkte
- Simulationsmethoden & Implementierung in Isaac Sim / Isaac Lab
- Vergleich & RL-basierte Bewertung
Weitere Informationen
Infos auf Anfrage. Bewerbung per E-Mail mit Lebenslauf und Notenübersicht.
[PA, MA] Analyse einer Simulationsumgebung zur Auslegung von Torodialmagnetfeldern

Die Auslegung von Toroidalmagnetfeldern ist eine zentrale Grundlage für zahlreiche Anwendungen in der Energietechnik und Magnetentwicklung, insbesondere im Umfeld supraleitender Systeme und zukünftiger Fusionsanlagen. Dabei müssen Feldverteilungen, Geometrieeinflüsse, Randbedingungen und Auslegungsparameter in geeigneten Simulationsumgebungen zuverlässig abgebildet und bewertet werden. Insbesondere bei komplexen Spulengeometrien, gekrümmten Leiterverläufen und hohen Anforderungen an Feldqualität, Nachvollziehbarkeit und Modellgüte sind systematische Analyse und Validierung der verwendeten Simulationswerkzeuge von großer Bedeutung. Ziel dieser Arbeit ist die Analyse bestehender Simulationsumgebungen zur Auslegung von Toroidalmagnetfeldern. Der Fokus liegt auf dem strukturierten Verständnis der zugrunde liegenden Modelle, der Bewertung von Parametereinfluss und Aussagekraft sowie der Untersuchung der Eignung der Umgebung für die magnetische Auslegung und den späteren Einsatz im Forschungskontext.
Aufgabenstellung
- Einarbeitung in die bestehenden Simulationsumgebungen, die physikalischen Grundlagen von Toroidalmagnetfeldern und die relevanten Randbedingungen der magnetischen Auslegung
- Analyse des Aufbaus der Simulationsumgebung hinsichtlich Modellstruktur, Eingangsgrößen, Randbedingungen und Ergebnisdarstellung
- Untersuchung der zugrunde liegenden Annahmen, Vereinfachungen und Grenzen der verwendeten Modellierung
- Durchführung systematischer Simulationsstudien zur Bewertung des Einflusses wesentlicher Auslegungsparameter auf Feldverteilung und Feldcharakteristik
- Analyse der Sensitivität gegenüber geometrischen, elektrischen und magnetischen Eingangsgrößen
- Bewertung der Aussagekraft und Plausibilität der Simulationsergebnisse anhand physikalischer Zusammenhänge und gegebenenfalls verfügbarer Referenzdaten
- Identifikation möglicher Schwachstellen, Unsicherheiten oder Verbesserungspotenziale innerhalb der Simulationsumgebung
- Erarbeitung von Ansätzen zur strukturierten Nutzung, Erweiterung oder methodischen Verbesserung der Umgebung für zukünftige Auslegungsaufgaben
- Dokumentation der Ergebnisse sowie Aufbereitung der gewonnenen Erkenntnisse für die weitere Nutzung im Team
Anforderungen
- Gute Kenntnisse in Elektrotechnik, Mechatronik, Physik, Maschinenbau oder einem verwandten technischen Bereich
- Interesse an elektromagnetischen Fragestellungen, numerischer Simulation und physikalischer Modellbildung
- Grundkenntnisse in mathematischer Modellierung und technischer Auswertung
- Sehr gute Programmierkenntnisse, idealerweise in Python, C++, Matlab oder einer vergleichbaren Umgebung
- Erfahrungen mit Simulationstools oder elektromagnetischen Berechnungen
- Strukturierte, eigenständige und sorgfältige Arbeitsweise sowie Teamfähigkeit
- Sehr gute Deutsch und/oder Englischkenntnisse in Wort und Schrift
Weitere Informationen
Weitere Informationen und Details sind bei den genannten Mitarbeitern erhältlich. Eine Bearbeitung ist ab sofort möglich. Bewerbungen senden Sie bitte mit aktuellem Notenauszug, relevanten Zeugnissen, Sprach Level Nachweis bei nicht muttersprachlichem Deutsch oder Englisch sowie Lebenslauf per E Mail. Ich werde mich zeitnah rückmelden.
[BA, PA, MA] Entwicklung eines kamera und KI gestützten Roboterverfahrens zur automatisierten Einbringung paralleler Drähte in Statornuten

Kamera und KI gestützte Roboterprozesse eröffnen neue Möglichkeiten für die präzise und flexible Fertigungsprozesse. Insbesondere bei der Handhabung biegeschlaffer Bauteile, geometrischen Toleranzen und hohen Anforderungen an Prozesssicherheit, Wiederholgenauigkeit und Robustheit sind konventionelle, rein vorgeplante Abläufe nur eingeschränkt geeignet. Ziel dieser Arbeit ist die Entwicklung eines kamera und KI gestützten Roboterprozesses zur zuverlässigen Erkennung, Lagebewertung und automatisierten Einbringung paralleler Drähte in Statornuten. Der Fokus liegt auf der durchgängigen Verbindung von Bildverarbeitung, intelligenter Prozessentscheidung und robotischer Ausführung einschließlich geeigneter Schnittstellen, Validierungsstrategien und Bewertung der Prozessfähigkeit.
Aufgabenstellung
- Einarbeitung in den bestehenden Versuchsaufbau, die Prozessanforderungen und die Randbedingungen der Drahteinbringung in Statornuten
- Analyse des Ist Zustands hinsichtlich Drahtlage, Toleranzen, relevanter Fehlerbilder und bisheriger Handhabungsstrategien
- Konzeption eines kamera gestützten Systems zur Erkennung und Bewertung der Drahtposition sowie der relevanten Prozessmerkmale
- Entwicklung geeigneter KI basierter Ansätze zur Detektion, Klassifikation oder Lagebewertung der Drähte und zur Unterstützung der Prozessentscheidung
- Auslegung und Implementierung eines robotergestützten Prozesses zur automatisierten Einbringung paralleler Drähte in Statornuten
- Entwicklung geeigneter Strategien zur Bahnplanung, Korrekturbewegung und robusten Prozessführung bei Abweichungen im realen Aufbau
- Integration der Bildverarbeitung und KI Verfahren in die bestehende Roboter und Steuerungsumgebung
- Inbetriebnahme und experimentelle Validierung des Gesamtsystems hinsichtlich Erkennungsqualität, Wiederholgenauigkeit, Prozessstabilität und Robustheit
- Dokumentation der Ergebnisse sowie Aufbereitung der entwickelten Methoden für die weitere Nutzung im Team
Anforderungen
- Gute Kenntnisse in Robotik, Automatisierung, Mechatronik oder einem verwandten technischen Bereich
- Interesse an Bildverarbeitung, maschinellem Lernen oder KI gestützten Verfahren in der Produktion
- Grundkenntnisse in Programmierung, idealerweise in Python oder C++
- Erfahrungen mit ROS, Kamera Systemen, Machine Vision oder der Verarbeitung von Sensordaten sind von Vorteil
- Strukturierte, eigenständige und sorgfältige Arbeitsweise sowie Teamfähigkeit
- Sehr gute Deutsch und/oder Englischkenntnisse in Wort und Schrift
Weitere Informationen
Weitere Informationen und Details sind bei den genannten Mitarbeitern erhältlich. Eine Bearbeitung ist ab sofort möglich. Bewerbungen senden Sie bitte mit aktuellem Notenauszug, relevanten Zeugnissen, Sprach Level Nachweis bei nicht muttersprachlichem Deutsch oder Englisch sowie Lebenslauf per E Mail. Wir werden uns zeitnah rückmelden.