Index
Prototyp einer self-managed Multi-Cluster-Architektur für die Edge (BA/PA/MA)

Der Einsatz von Edge Computing gewinnt in vielen Bereichen an Bedeutung, da er die Datenverarbeitung näher an den Ort der Datenentstehung verlagert und damit Latenzen, Bandbreitenbedarf sowie Abhängigkeiten von Cloud-Verbindungen reduziert. Gleichzeitig steigen die Anforderungen an Automatisierung, Lifecycle Management und Fleet Operations, weil Edge-Knoten oft heterogen sind, in instabilen Netzen laufen und nur eingeschränkt an verteilten Ort gewartet werden können.
Ziel dieser studentischen Arbeit ist der Aufbau und die prototypische Evaluation einer self-managed Edge-Kubernetes-Referenzarchitektur (hub-and-spoke), die zunächst virtuelle Edge Devices (VMs auf Proxmox VE und/oder OpenStack) nutzt und später auf dedizierte Hardware übertragbar ist. Im Fokus steht eine reproduzierbare Day-0 Provisioning Pipeline via (i)PXE boot sowie first-boot configuration mit cloud-init und Ignition/Combustion (optional unter Nutzung von Matchbox). Darauf aufbauend sollen mehrere Linux- und Kubernetes-Cluster-Varianten automatisiert gestartet und zentral mit GitOps sowie Fleet-style Multi-Cluster Rollout verwaltet werden.
(Mögliche) Schwerpunkte der Arbeit:
- Design & Implementierung einer hub-and-spoke Referenzarchitektur für self-managed Edge Kubernetes (Management Cluster + Edge Spokes).
- Provisioning Pipeline: Klassisches (i)PXE, darauf aufbauendes Netboot mittels HTTPBoot via UEFI or U-Boot oder je nach BMC auch IPMI/Redfish, Profilverwaltung (optional Matchbox) und Konfiguration via Ignition/Combustion/cloud-init. Parallel dazu Lifecycle Management mittels Cluster API und entsprechendem Provider (z.B. CAPM3 (Metal³ im Falle OpenStack Ironic) oder CAPT (Tinkerbell im Falle von einfachem iPXE/Netboot))
- Definition von stabilen Cluster-Profilen (z.B. Talos Linux, openSUSE Leap Micro + k3s, Ubuntu + MicroK8s oder Debian + k0s) inkl. automatisiertem Bootstrap und Re-Provisioning (replaceable nodes).
- GitOps-gestützte Baseline: Standardisierte Installation von Add-ons (z. B. Longhorn, Ingress, Observability) über Argo CD oder Flux.
- Persistence & Registry Integration: Longhorn als persistence storage, Deployment-Pipeline über GitLab CI/CD, GitLab Container Registry, Harbor als Proxy Cache und Replication Bridge / Pull-Through Cache (ggf. zunächst lediglich GitLab Dependency Proxy für Docker Hub) und optional K3s Spegel.
- Dokumentation & Demonstrator: Nachvollziehbare Architektur-/Betriebsdokumentation, IaC/Automation in einem Git-Repository sowie eine Demo-Umgebung als Testbed für Forschung/Lehre.
Ausblick auf darauf aubauende Arbeiten:
- Erweiterung des Lifecycle Managements um Foreman und Katello.
- Fleet-style Multi-Cluster Rollout: Vergleich und Bewertung von Rancher Fleet, Argo CD ApplicationSet und Flux (optional Open Cluster Management (OCM) / Karmada) anhand definierter Kriterien (Drift, Skalierbarkeit, Multi-tenancy, Offline-Toleranz, Usability usw.).
- Integration und Reifegradbewertung von KubeEdge/OpenYurt oder LF Edge Komponenten (FIDO Device Onboard, EVE-OS, EdgeX Foundry) im Rahmen der bestehenden Architektur.
Wenn die ausgeschriebene Arbeit noch online ist, dann ist sie auch noch aktuell. Sollten Sie Interesse an der Arbeit haben, so kommen Sie bitte mittels einer E-Mail (in der Sie kurz Ihr Vorwissen darstellen) auf mich zu. Sollten Sie eine intrinsische Motivation für ein angrenzendes oder ähnlichen Thema haben, so stellen Sie in Ihrer Anfrage bitte den Bezug zu meiner Ausschreibung dar.
Bitte stellen Sie die komplette Anfrage in deutscher Sprache, auch wenn Sie die Ausarbeitung in Englisch verfassen werden. Hintergrund ist, dass Sie sich in laufende Forschungsprojekte einbringen mit den Unternehmen austauschen können sollen und von diesen wird mehrheitlich eine Kommunikation auf Deutsch gewünscht.
Weitere Informationen erhalten Sie auf Anfrage, der Arbeitsumfang kann entsprechend der Arbeit angepasst werden und die Bearbeitung weitestgehend im Home-Office stattfinden.
Realisierung eines Mixed-SBC-Clusters für die Edge (BA/PA/MA)
Der Einsatz von Edge Computing gewinnt in vielen Bereichen an Bedeutung, da er die Datenverarbeitung näher an den Ort der Datenentstehung verlagert und damit Latenzen, Bandbreitenbedarf sowie Abhängigkeiten von Cloud-Verbindungen reduziert. Ein Mixed-SBC-Cluster, der verschiedene Single Board Computer (SBC) wie Nvidia Jetson, Raspberry Pi und verschiedene Hardwareerweiterungen umfasst, bietet eine ausgezeichnete Plattform, um die Herausforderungen und Möglichkeiten des Edge Computings zu erproben und zu demonstrieren.
Ziel ist die Entwicklung eines Mixed-SBC-Clusters für die Edge, der als experimentelle Plattform in industrienaher Forschung und für Lehrzwecke im Automatisierungsumfeld dient. Dieser Cluster soll die Heterogenität realer OT-Infrastrukturen bedienen und das Sammeln praktischer Erfahrungen mit Cluster-Management, verteilten Speichersystemen und der Integration von Erweiterungsmodulen (z.B. Funkmodul, Neural Processing Unit und Field Programmable Gate Array) eröffnen.
(Mögliche) Schwerpunkte der Arbeit:
- Aufbau und Konfiguration eines heterogenen SBC-Clusters für Edge Computing Szenarien.
- Einsatz eines Cluster-Management-Systems und Implementierung eines Service Mesh.
- Einsatz von Automatisierungswerkzeugen und Infrastruktur-as-Code (IaC) zur effizienten Verwaltung und Konfiguration.
- Implementierung eines Lifecycle-Managements des Betriebs bestehend aus Monitoring, Sicherung, Wartung und Aktualisierung.
- Integration von Storage-Lösungen und spezifischen Erweiterungsmodulen für verschiedene Anwendungsfälle.
- Integration in Anwendungsfälle der Automatisierungstechnik in industriellen Produktionsanlagen, der Gebäudeautomatisierung und insbesondere des Energiemanagements.
- Beitrag zum Transfer in die Lehre als Praktikumsversuch oder Übungseinheit
Wenn die ausgeschriebene Arbeit noch online ist, dann ist sie auch noch aktuell. Sollten Sie Interesse an der Arbeit haben, so kommen Sie bitte mittels einer E-Mail (in der Sie kurz Ihr Vorwissen darstellen) auf mich zu. Sollten Sie eine intrinsische Motivation für ein angrenzendes oder ähnlichen Thema haben, so stellen Sie in Ihrer Anfrage bitte den Bezug zu meiner Ausschreibung dar.
Bitte stellen Sie die komplette Anfrage in deutscher Sprache, auch wenn Sie die Ausarbeitung in Englisch verfassen werden. Hintergrund ist, dass Sie sich in laufende Forschungsprojekte einbringen mit den Unternehmen austauschen können sollen und von diesen wird mehrheitlich eine Kommunikation auf Deutsch gewünscht.
Weitere Informationen erhalten Sie auf Anfrage, der Arbeitsumfang kann entsprechend der Arbeit angepasst werden und die Bearbeitung weitestgehend im Home-Office stattfinden.
Intelligente Prozessoptimierung beim Richten von Flachdraht für elektrische Antriebe [BA/PA/MA]

Hintergrund
Die Fertigung elektrischer Antriebe, wie etwa Hairpin-, Continuous-Hairpin- oder Axialflussmaschinen, erfordert eine präzise Kontrolle von Material und Prozess. Ein zentraler Schritt ist das Richten von Flachdraht, das bislang auf festen Parametern und Erfahrungswissen basiert. Dabei werden Schwankungen im Material nur unzureichend berücksichtigt. Das Ziel besteht darin, diesen Prozess mithilfe moderner Sensorik, Messtechnik und innovativer Regelungsansätze weiterzuentwickeln, um die Produktionsqualität effizient zu steigern.
Mögliche Aufgabenstellungen
Studentische Arbeiten können zu einem der folgenden Themen erarbeitet werden:
- Integration und Validierung eines Wirbelstromprüfsystems zur Analyse von Eigenspannungen beim Richten von Flachdraht.
- Integration eines induktiven Abstandssensors zur Schichtdickenmessung
- Erweiterung der prototypischen Versuchsanlage um Sicherheitstechnik
- Modellierung und Simulation des Richtprozesses
- Weiterentwicklung einer flexiblen, mechanischen Abisolierstation für Flachdraht
- SPS-Programmierung einer Schwenkbiege-Anlage zum 2D-Biegen von Flachdraht
Die detaillierten Inhalte und Aufgabenstellungen werden in einem persönlichen Gespräch besprochen.
Anforderungsprofil
- Interesse an der Produktion elektrischer Traktionsantriebe
- Je nach Themengebiet sind Grundkenntnisse in Konstruktion, Messtechnik, Programmierung, Datenanalyse (KI/ML) oder Regelungstechnik erforderlich.
- Freude an praktischer Arbeit (Versuchsreihen, Messtechnik, Anlagenaufbau)
- Analytisches, strukturiertes und selbstständiges Arbeiten
- Teamfähigkeit und Kommunikationsstärke
- Gute Deutsch- und Englischkenntnisse in Wort und Schrift
Bewerbung
Bitte senden Sie Ihre Bewerbung mit
- Lebenslauf
- Aktuellem Notenspiegel
- Angabe der bevorzugten Aufgabenstellung
per E-Mail an anja.preitschaft@faps.fau.de
Wichtig: Bewerbungen ohne konkrete Nennung eines Themenbereichs können leider nicht bearbeitet werden.
Analyse und Bewertung von Aluminium-Flachdraht für Hairpin-Statoren – Systematische Literaturrecherche [BA/PA/MA]

Motivation
Im Zuge der Transformation der Mobilität gewinnen elektrische Traktionsantriebe zunehmend an Bedeutung. Besonders die Hairpin-Technologie hat sich in der industriellen Serienfertigung von Elektromotoren etabliert, da sie hohe Leistungsdichten und eine gute Automatisierbarkeit ermöglicht. In konventionellen Hairpin-Statoren werden überwiegend Kupferflachleiter eingesetzt.
Vor dem Hintergrund steigender Rohstoffpreise, Gewichtseinsparungen sowie Nachhaltigkeitsaspekten rückt jedoch der Einsatz alternativer Leiterwerkstoffe – insbesondere Aluminium – verstärkt in den Fokus von Forschung und Industrie. Aluminium-Flachdraht bietet potenzielle Vorteile hinsichtlich Kosten und Gewicht, stellt jedoch gleichzeitig neue Herausforderungen für Fertigungsprozesse, Verbindungstechnologien sowie elektrische und thermische Eigenschaften dar.
Ziel dieser studentischen Arbeit ist daher eine systematische Literaturrecherche und Analyse des aktuellen Stands der Technik zu Aluminium-Flachdraht in Hairpin-Statoren sowie die Identifikation von Forschungs- und Entwicklungsbedarfen entlang der Prozesskette der Statorfertigung.
Mögliche Aufgabenstellungen
Im Rahmen der Arbeit sollen wissenschaftliche Veröffentlichungen, Patente und industrielle Ansätze analysiert und strukturiert ausgewertet werden. Mögliche Schwerpunkte sind:
- Systematische Literaturrecherche zu Aluminium-Flachleitern für elektrische Traktionsmaschinen
- Analyse des aktuellen Stands der Technik von Hairpin-Statoren und der verwendeten Leiterwerkstoffe
- Untersuchung der elektrischen, thermischen und mechanischen Eigenschaften von Aluminium im Vergleich zu Kupfer
- Bewertung der Auswirkungen auf Fertigungsprozesse, zum Beispiel
- Drahtziehen und Richtprozesse
- Biegeprozesse von Hairpins
- Kontaktierungs- und Verbindungstechnologien (z. B. Schweißen, Crimpen, Löten)
- Analyse möglicher Isolations- und Beschichtungssysteme für Aluminiumleiter
- Strukturierte Aufbereitung der Ergebnisse und Identifikation von Forschungslücken
- Ökonomische und ökologische Bewertung des Einsatzes von Aluminiumleitern
- Ableitung von Handlungsempfehlungen für zukünftige Forschungsarbeiten
Anforderungsprofil
- Studium im Bereich Maschinenbau, Mechatronik, Elektrotechnik, Wirtschaftsingenieurwesen oder verwandter Studiengänge
- Interesse an elektrischen Antrieben und deren Fertigungstechnologien
- Grundkenntnisse in Werkstoffkunde, Elektromaschinenbau oder Produktionstechnik von Vorteil
- Interesse an wissenschaftlicher Recherche und Analyse
- Selbstständige, strukturierte und sorgfältige Arbeitsweise
- Gute Deutsch- und Englischkenntnisse in Wort und Schrift
Bewerbung
Bei Interesse senden Sie bitte Ihre Bewerbung mit:
- Lebenslauf
- aktuellem Notenspiegel
per E-Mail an anja.preitschaft@faps.fau.de
[BA/PA/MA] – Aufbereitung und Strukturierung industrieller Fertigungsdaten für das Training eines prozessübergreifenden World Models
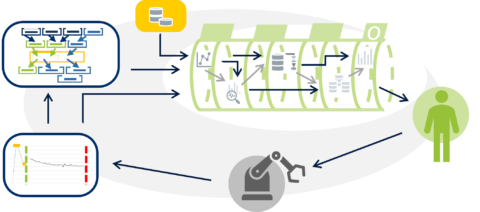
Ausgangssituation:
Moderne Fertigungsprozesse erzeugen große Mengen multimodaler Maschinendaten, die das Potenzial bieten, datengetriebene Modelle für verschiedenste Anwendungsfälle wie Predictive Quality, Predictive Maintenance oder Prozessoptimierung zu trainieren. Ein vielversprechender Ansatz ist das Konzept eines World Models, das die Zusammenhänge zwischen Prozesseingangsdaten, Zielgrößen und Stellgrößen bzw. Aktionen ganzheitlich lernt. Voraussetzung dafür ist ein strukturierter, qualitativ hochwertiger Datensatz, der Maschinendaten verschiedener Modalitäten und Quellen auf Sample-Ebene mit geeigneten Ziel- und Regelgrößen verknüpft. Aktuell liegen diverse industrielle Datensätze unterschiedlicher Prozesse sowie öffentlich verfügbare industrielle Referenzdatensätze vor, die als Grundlage für ein solches Vorhaben dienen sollen.
Keywords:
Data Engineering, Datenanalyse, World Model, Predictive Quality, Predictive Maintenance, industrielle Fertigungsdaten, multimodale Daten
Aufgabenstellungen:
Ziel der Arbeit ist die methodische Aufbereitung, Analyse und Strukturierung heterogener industrieller Datensätze, sodass diese als Trainingsgrundlage für ein prozessübergreifendes World Model genutzt werden können. Die Aufgabenstellung umfasst die folgenden Arbeitspakete:
- Fachliche Einarbeitung in die Themenfelder Data Engineering für industrielle Fertigungsdaten, World Models sowie relevante Anwendungsfälle (Predictive Quality, Predictive Maintenance, Prozesssteuerung)
- Analyse, Bereinigung und ggf. Korrektur der vorliegenden Maschinendaten und Zielgrößen unterschiedlicher Modalitäten und Quellen
- Identifikation und Extraktion geeigneter Regelgrößen aus den Maschinendaten, die als Aktionen des World Models dienen
- Verknüpfung der Eingangsdaten (X), Aktionen (a) und Zielgrößen (y) zu einem konsistenten, strukturierten Datensatz auf Sample-Ebene
- Entwicklung einer geeigneten Datenstruktur, die sowohl eine einfache Analyse und Visualisierung als auch ein performantes Laden für das Modelltraining ermöglicht
- Entwicklung eines interaktiven Dashboards zur Visualisierung, Filterung und Erzeugung von Train-/Validation-/Test-Splits inkl. wählbarer Skalierungsmethoden
Anforderungsprofil und Informationen zur Bewerbung:
- Interesse an datengetriebenen Methoden im industriellen Umfeld, idealerweise erste Erfahrungen im Bereich Data Engineering oder Datenanalyse
- Hohe Motivation, Auffassungsgabe sowie strukturierte Arbeitsweise und gute Kommunikationsfähigkeiten
- IT-Affinität und gute Kenntnisse mindestens einer Hochsprache (idealerweise Python) wünschenswert
- Bearbeitungsbeginn ab sofort möglich
- Umfang und Inhalte je nach Arbeit (BA/PA/MA) und Präferenzen individuell abstimmbar
- Bewerbungen bitte mit CV und aktueller Fächer-/Notenübersicht per Mail an unten genannten Kontakt
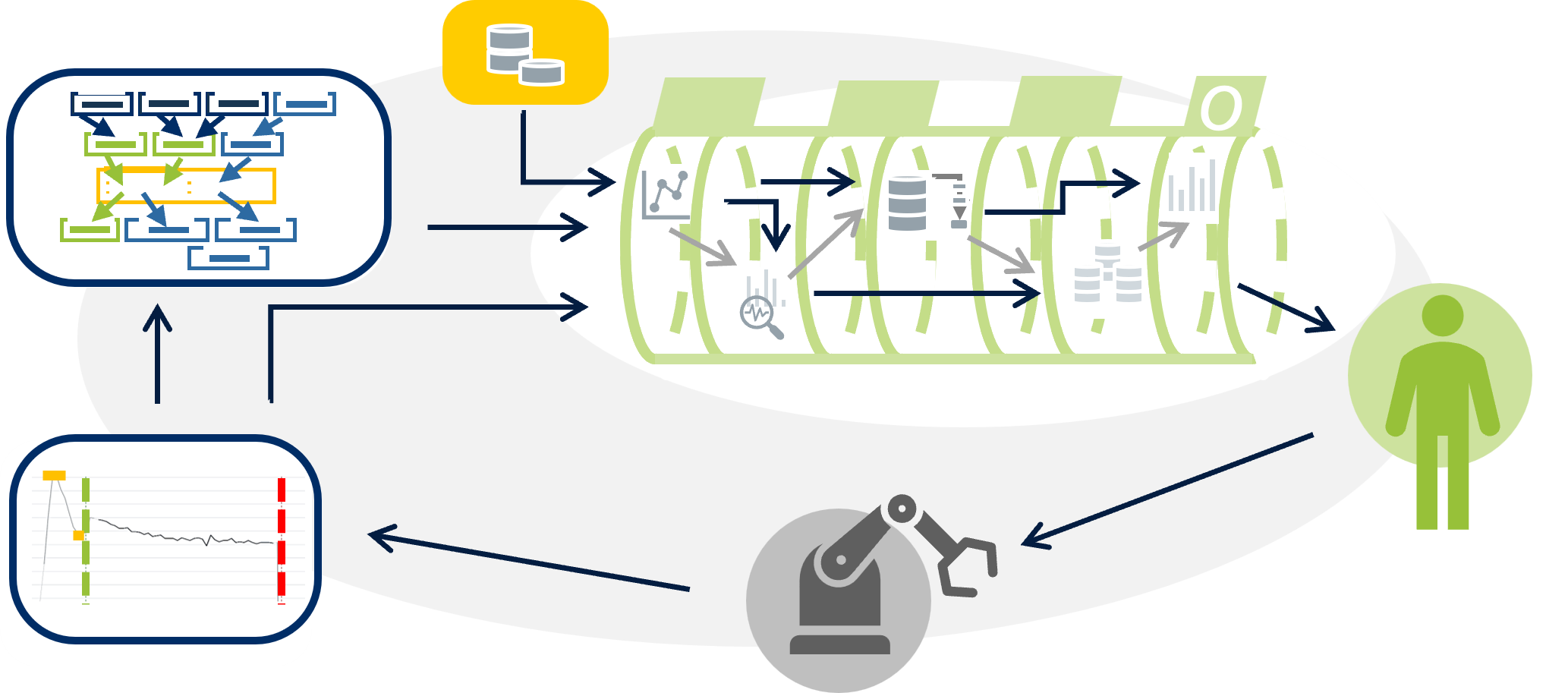
[BA/PA/MA] Weiterentwicklung eines Sensordemonstrators zur automatisierten Erzeugung multimodaler Trainingsdaten für ein handlungsfähiges World Model

Ausgangssituation:
Am Lehrstuhl FAPS besteht ein modularer Sensordemonstrator, der im Rahmen einer Masterarbeit entwickelt und in Betrieb genommen wurde. Der Demonstrator bildet eine miniaturisierte Produktionsanlage ab und umfasst einen drehbaren Materialbereitsteller mit zwei Lagertürmen, einen pneumatischen Schwenkarm mit Vakuumgreifer, einen Bearbeitungsbereich mit Drehteller, Stempel und Kamera-basierter Qualitätskontrolle (OpenCV/ML) sowie ein Förderband mit drei Weichen zur Materialverteilung. Die Anlage wird über eine Siemens SPS (S7-1500) gesteuert und verfügt über eine Vielzahl verbauter Sensoren unterschiedlicher Modalitäten – darunter optische Abstandssensoren, kapazitive und induktive Näherungsschalter, Drucksensoren, Lichtschranken, eine Industriekamera sowie mechanische Endschalter – und pneumatischer wie elektrischer Aktoren.
Langfristiges Ziel ist es, auf Basis dieses Demonstrators ein sogenanntes World Model zu entwickeln: ein datengetriebenes Prozessmodell, das Zustände, Aktionen und deren Auswirkungen intern abbildet und so eine ganzheitliche, vorausschauende Optimierung des Betriebs ermöglicht. Um ein solches Modell trainieren zu können, wird ein geeigneter Trainingsdatensatz benötigt, der multimodal (Zeitreihen, Bilddaten etc.), domänenübergreifend (verschiedene Produkte und Prozessvarianten) und handlungsorientiert (mit expliziten Aktionen und Störungen) aufgebaut ist. Ziel dieser Arbeit ist die Erzeugung dieses Datensatzes – sowie die dafür nötige Erweiterung und Automatisierung des Demonstrators.

Keywords:
World Model, Domain Generalization, Multimodal Dataset, Sensordemonstrator, SPS, Design of Experiments, Predictive Quality, Predictive Maintenance, Anomaly Detection, Industrie 4.0
Aufgabenstellungen:
Ziel der Arbeit ist die systematische Erstellung eines domänenübergreifenden, multimodalen Datensatzes auf Basis des bestehenden Sensordemonstrators, der zum späteren Training eines handlungsfähigen World Models geeignet ist. Der Datensatz soll auf Sample-Ebene die Eingangsdaten aller Sensormodalitäten (X), die anwendungsfallspezifischen Labels (y; Qualität, Störung, Anomalie etc.) sowie die jeweils zugrunde liegenden Aktionen (a) zeitsynchron enthalten. Durch den Aufbau über mehrere Domänen hinweg (z. B. unterschiedliche Produkte, Maschinen oder Prozessvarianten) soll der Datensatz später ein domänenübergreifendes Lernen (Domain Generalization) ermöglichen. Darüber hinaus soll der Datensatz möglichst viele industrielle Anwendungsfälle abdecken können, darunter Predictive Quality, Predictive Maintenance und Anomaly Detection. Die Aufgabenstellung umfasst die folgenden Arbeitspakete:
- Bestandsaufnahme: Systematische Dokumentation des Ist-Zustands des Demonstrators (verbaute Sensorik, Aktorik, SPS-Programm, Datenflüsse, bestehende Steuerungsszenarien). Identifikation der vorhandenen Sensormodalitäten (Zeitreihen, Bilddaten, binäre Signale etc.) und Bewertung der Datenlage als Grundlage für einen multimodalen Datensatz.
- Evaluierung und Integration von Aktionen: Identifikation und Bewertung möglicher Stellgrößen, die als Aktionen in den Prozess integriert und über die SPS variiert werden können (z. B. Bandgeschwindigkeit, Stempeldruck/-dauer, Schwenkgeschwindigkeit, Drehteller-Taktung, Weichenlogik). Auswahl und Implementierung geeigneter Aktionen, sodass deren Auswirkungen auf die Sensordaten und den Prozessausgang messbar werden.
- Konzeption und Einbringung von Störungen: Überprüfung, welche Prozessstörungen realistisch erzeugt oder simuliert werden können (z. B. Druckabfall, Sensorausfall/-degradation, Werkstückvarianz, Bandstopp). Integration ausgewählter Störszenarien in den Demonstratorbetrieb, um Trainingsdaten für Anomaly Detection und Predictive Maintenance zu generieren.
- Domänenkonzept und Qualitätssimulation: Definition von Domänen für den Datensatz, z. B. unterschiedliche Werkstückvarianten (Material, Farbe, Geometrie) oder Prozessvarianten (Szenarien, Parameterregime). Erarbeitung eines Konzepts zur Simulation bzw. kontrollierten Erzeugung von Produktqualitätsunterschieden, um gelabelte Qualitätsdaten für Predictive Quality zu erhalten. Perspektivisch existiert eine zweite, baugleiche Demonstratorinstanz, die eine Generalisierung über Maschineninstanzen hinweg ermöglichen könnte.
- Umrüstung, Programmierung und modulare Softwarearchitektur: notwendige Hardware-Erweiterungen sowie Anpassung/Erweiterung des SPS-Programms und der Datenerfassungs-Pipeline. Der Steuerungscode soll modular aufgebaut werden und definierte Schnittstellen bereitstellen, über die später ein trainiertes World Model eingebunden werden kann, um den Demonstrator in Echtzeit basierend auf Modellvorhersagen zu regeln.
- Automatisierte Versuchsdurchführung (DoE): Entwicklung eines Programms, mit dem ein Design of Experiments basierend auf konfigurierbaren Eingaben (Aktionsparameter, Störszenarien, Domänen) erzeugt und automatisiert am Demonstrator durchgeführt werden kann. Das Programm soll wiederverwendbar sein, damit zu einem späteren Zeitpunkt unkompliziert weitere Daten generiert werden können.
- Datensatzerstellung, Dokumentation und Bewertung: Durchführung der Versuchsreihe und Erstellung des strukturierten Datensatzes. Jedes Sample soll die multimodalen Sensordaten (X), die anwendungsfallspezifischen Labels (Qualität, Störung, Anomalie etc.) und die zugrunde liegenden Aktionen (a) enthalten. Dokumentation des Datensatzformats, Datenqualitätsanalyse und Diskussion der Eignung für das Training eines domänenübergreifenden, multimodalen und handlungsfähigen World Models.
Anforderungsprofil und Informationen zur Bewerbung:
- Interesse an Automatisierungstechnik und datengetriebener Prozessoptimierung
- Grundkenntnisse in SPS-Programmierung (idealerweise Siemens TIA Portal) oder hohe Bereitschaft zur Einarbeitung
- Gute Programmierkenntnisse (idealerweise Python) für Datenerfassung, Versuchsautomatisierung und Schnittstellenentwicklung
- Praktisches Geschick im Umgang mit Hardware (Sensorik, Aktorik, Pneumatik) von Vorteil
- Idealerweise Grundverständnis von Machine Learning und Versuchsplanung (Design of Experiments)
- Hohe Motivation, strukturierte Arbeitsweise und gute Kommunikationsfähigkeiten
- Bearbeitungsbeginn ab sofort möglich
- Umfang und Inhalte je nach Arbeit (BA/PA/MA) und Präferenzen individuell abstimmbar
- Bewerbungen bitte mit CV und aktueller Fächer-/Notenübersicht per Mail an unten genannten Kontakt
BA/PA: LLM-basierte Service-Automatisierung im Maschinenbau: Systematische Analyse der Prozessphasen klassicher Vorgehensmodelle
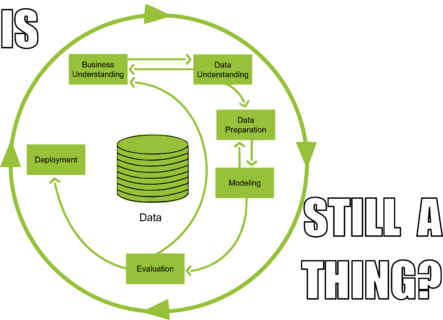
Kontext und Motivation
Service-Exzellenz ist einer der letzten verbleibenden Wettberwerbsvorteile deutscher Hidden Champions aus dem mittelständischen Maschinen- und Anlagenbau, um sich im Umfeld eines zunehmenden internationalen Preisdrucks zu behaupten. Doch der Fachkräftemangel einerseits und der drohende Wissensabfluss durch den bevorstehenden Renteneintritt maßgeblicher Service-Experten der Babyboomer-Generation andererseits gefährden diesen Vorsprung.
Generative KI verspricht hier Abhilfe zu schaffen: Durch die automatisierte Bearbeitung insbesondere einfacher technischer Kundenanfragen auf Basis des aktuell noch meist implizit vorliegenden Wissenschatzes der Unternehmen soll technischer Kundenservice durch Entlastung und gezielten Einsatz der verbleibenden Experten skalierbar gemacht werden.
Eine Herausforderung hierbei ist, dass etablierte Vorgehensmodelle für KI-Projekte wie etwa CRISP-DM aus einer Zeit von strukturierten Tabellendaten und prädiktiven Modellen stammen (Narrow AI). Es stellt sich daher die Frage in wie weit solch klassische Vorgehensmodelle für die Umsetzung LLM-basierter Anwendungen valide bleiben beziehungsweise welche Anpassungen für eine Erfolgreiche Umsetzung LLM-basierter Anwendungen nötig sind.
Ziel der Arbeit
Im Rahmen dieser Arbeit soll eine Systematic Literature Review (SLR) durchgeführt werden, um zu untersuchen, wie sich die Phasen des CRISP-DM-Modells für LLM-Projekte im industriellen Service-Kontext bereits verändert haben beziehungsweise verändern müssen.
Mögliche Schwerpunkte
Die Ausschreibung ist so konzipiert, dass verschiedene Studierende jeweils einzelne Phasen des CRISP-DM tiefgreifend analysieren können. Die Phasen des CRISP-DM:
- Business Understanding
- Data Understanding
- Data preparation
- Modeling
- Evaluation
- Deployment
Je nach Schwerpunkt der Arbeit werden initial zu unteruschende Forschungs- beziehungsweise Leitfragen definiert.
Aufgabeninhalte
- Durchführung einer strukturierten Literaturrecherche (z. B. via Scopus, Web of Science, IEEE Xplore).
- Identifikation von Anpassungsbedarfen des CRISP-DM-Modells für generative Wissensverarbeitung.
- Synthese der Ergebnisse: Welche Frameworks (z. B. FMDev, LLMOps) schlägt die Forschung als Nachfolger oder Ergänzung vor?
- Bezugnahme auf die spezifischen Herausforderungen im Maschinenbau beziehungsweise technischen Kundendienst (technische Komplexität, Sicherheit, Prompt Injection).
Vorkenntnisse
- Technischer Studiengang
- Idealerweise Vorkenntnisse bei der Durchführung von Literaturrechcherchen
- Interesse an Generativer KI, Knowledge Management und Prozessmodellen, idealerweise mit Vorkenntnis der technischen Hinterründe
- Strukturierte Arbeitsweise
- Gute Englisch-Kenntnisse für das Verständnis der Fachliteratur
Weitere Informationen auf Anfrage. Bewerbungen bitte per E-Mail mit aktueller Notenübersicht und Lebenslauf
Generative KI im Systems Engineering

Im Forschungsprojekt LLM-SE (Large Language Model unterstütztes Systems Engineering) wird am Lehrstuhl für Fertigungsautomatisierung und Produktionssystematik (FAPS) ein neuartiger Ansatz zur KI-gestützten Teilautomatisierung des Systems Engineerings mechatronischer Systeme entwickelt. Ziel ist es, Engineering-Prozesse von der Anforderungsspezifikation über die Modellbildung bis hin zur virtuellen Inbetriebnahme methodisch zu strukturieren, teilautomatisiert zu unterstützen und systematisch zu validieren.
Ein zentraler Fokus des Projekts liegt auf der generativen Modellbildung entlang des RFLP-Ansatzes sowie auf der Kopplung dieser Modelle mit simulationsbasierten Methoden zur Validierung und Optimierung. Hierzu werden Large Language Models (LLMs) mit Wissensbasen, Optimierungsverfahren und Simulationswerkzeugen kombiniert. Die entwickelten Methoden werden an repräsentativen Anwendungsfällen mechatronischer Systeme demonstriert, evaluiert und dokumentiert.
Im Rahmen studentischer Arbeiten besteht die Möglichkeit, an diesen Fragestellungen mitzuwirken und Teilaspekte der Arbeitspakete AP 5 (KI-gestützte Modellbildung und Konfiguration) und AP 10 (Methodik, Demonstration und Validierung) zu bearbeiten.
Inhaltlicher Fokus der studentischen Arbeiten
KI-gestützte Modellbildung und Konfiguration
Ausgehend von Anforderungsspezifikationen werden funktionale Modelle, Lösungsstrukturen und Konfigurationen mechatronischer Systeme erzeugt. Dabei kommen LLM-basierte Verfahren, Wissensbasen sowie Optimierungsansätze zum Einsatz. Ziel ist es, aus einer Vielzahl möglicher Lösungen schrittweise konsistente und regelkonforme Systemmodelle abzuleiten.
Studierende können u. a. an folgenden Themen arbeiten:
-
Ableitung funktionaler Strukturen aus Anforderungen
-
Nutzung von LLMs zur Identifikation und Kombination geeigneter Lösungselemente
-
Aufbau und Nutzung von Wissensbasen zur Modellgenerierung
-
Erstellung von 150 %- und 100 %-Modellen entlang des RFLP-Ansatzes
-
KI-gestützte Unterstützung bei der Konfiguration physischer Systemelemente
Methodik, Demonstration und Validierung
Aufbauend auf den in AP 5 generierten Modellen wird ein methodisches Vorgehensmodell für LLM-gestütztes Systems Engineering entwickelt, erprobt und evaluiert. Dieses beschreibt die einzelnen Prozessschritte von der Anforderungserfassung bis zur virtuellen Validierung und definiert die entstehenden Artefakte.
Zentrale Aspekte sind:
-
Analyse und Abgrenzung bestehender Engineering-Vorgehensmodelle
-
Strukturierung der LLM-SE-Aktivitäten in ein konsistentes Prozessmodell
-
Anwendung des Vorgehensmodells auf reale und repräsentative Testfälle
-
Systematische Validierung der Ergebnisse entlang des Entwicklungsprozesses
-
Bewertung von Qualität, Effizienz und Robustheit der erzeugten Modelle
Simulationsbasierte Validierung und Optimierung
Ein verbindendes Element zwischen AP 5 und AP 10 ist die Kopplung der generierten Modelle mit Simulationsverfahren. Simulationen dienen dabei nicht nur der Validierung, sondern auch der gezielten Optimierung von Systementwürfen.
Mögliche Schwerpunkte sind:
-
Ableitung simulationsfähiger Modelle aus generierten Systembeschreibungen
-
Nutzung von Simulationen zur Bewertung alternativer Lösungsvarianten
-
Integration simulationsbasierter Kennzahlen (z. B. Qualität, Zeit, Kosten) in den Engineering-Prozess
-
Untersuchung des Zusammenspiels von LLMs, Simulation und Optimierungsverfahren
-
Identifikation von Verbesserungspotenzialen durch iterative Simulation und Anpassung der Modelle
Profil
-
Studium in Maschinenbau, Elektrotechnik, Mechatronik, Informatik oder vergleichbar
-
Kenntnisse in Unity (C#), TIA Portal oder EPLAN wünschenswert
-
Interesse an KI, Automatisierung und virtueller Inbetriebnahme
-
Selbstständige und strukturierte Arbeitsweise, Teamfähigkeit sowie gute Kommunikationsfähigkeiten
- Sehr gute Deutsch- und Englischkenntnisse in Wort und Schrift
Was wir bieten
-
Einbindung in ein aktuelles öffentlich gefördertes Forschungsprojekt
-
Hohe Zusammenarbeit mit regionalen Industriepartnern
Beginn
Ab sofort möglich. Die Position ist als Bachelor-, Projekt- oder Masterarbeit verfügbar.
Kontakt
Interessierte Studierende senden bitte ihre Bewerbungsunterlagen (kurzes Motivationsschreiben, Lebenslauf, Notenspiegel) per E-Mail an:
jan.krüger@faps.fau.de
Weitere Informationen zum Projekt LLM-SE:
LLM-SE auf faps.fau.de
Induktives Laden: Konzeption und Entwicklung von Prozessen zur automatisierten Produktion induktiver Energieübertragungssysteme (BA/PA/MA)

Ausgangslage:
Mit der fortschreitenden Elektrifizierung der Fahrzeuge steigt auch die Nachfrage nach komfortablen, sicheren und in den Alltag integrierbaren Lademöglichkeiten. Kontaktlose Energieübertragungssysteme ermöglichen Szenarien wie „Road Charging“ und „Opportunity Charging“. Weitere Vorteile sind ein gesteigerter Ladekomfort für den Anwender sowie eine geringere Angriffsfläche für Vandalismus. Folglich ist für die nächsten Jahre eine gesteigerte Nachfrage nach induktiven Energieübertragungssystemen für Elektromobile zu erwarten. Allerdings stehen bislang keine Verfahren zur Verfügung, die eine wirtschaftliche Fertigung induktiver Energieübertragungssysteme in hoher Stückzahl ermöglichen.
Mögliche Aufgabenstellung
Verlegen, Kontaktieren und Isolieren sind die drei wichtigsten Schritte zur Herstellung eines induktiven Energieübertragungssystems. Die Verfahren sollen durch geeignete Maßnahmen für die industrielle Fertigung befähigt werden. Neben praktischen Versuchen ist auch der prototypische Aufbau von Demonstratoren vorgesehen. Mögliche Aufgabenstellungen können sein:
- Einarbeiten in die Technologien für die kontaktlose Energieübertragung
- Analyse von verschiedenen Systemaufbauten der Marktbegleiter
- Adaption bestehender Konzepte aus dem Elektromaschinenbau auf den neuen Anwendungskontext
- Entwicklung und Konzeption geeigneter Vorrichtungen und Aufbau von Demonstratorsystemen
Hinweise und Bewerbung:
- Bearbeitung der Aufgaben im studentischem Team
- Strukturierte und selbstständige Arbeitsweise
- Bewerbungen bitte per E-Mail mit Lebenslauf und aktueller Fächerübersicht an info@seamless-energy.com
Ansprechpartner:
Maximilian Kneidl
Maximilian Kneidl, M.Sc. info@seamless-energy.com

Induktives Laden: Konzeption und Entwicklung von Prozessen zur automatisierten Produktion induktiver Energieübertragungssysteme (BA/PA/MA)

Ausgangslage:
Mit der fortschreitenden Elektrifizierung der Fahrzeuge steigt auch die Nachfrage nach komfortablen, sicheren und in den Alltag integrierbaren Lademöglichkeiten. Kontaktlose Energieübertragungssysteme ermöglichen Szenarien wie „Road Charging“ und „Opportunity Charging“. Weitere Vorteile sind ein gesteigerter Ladekomfort für den Anwender sowie eine geringere Angriffsfläche für Vandalismus. Folglich ist für die nächsten Jahre eine gesteigerte Nachfrage nach induktiven Energieübertragungssystemen für Elektromobile zu erwarten. Allerdings stehen bislang keine Verfahren zur Verfügung, die eine wirtschaftliche Fertigung induktiver Energieübertragungssysteme in hoher Stückzahl ermöglichen.
Mögliche Aufgabenstellung
Verlegen, Kontaktieren und Isolieren sind die drei wichtigsten Schritte zur Herstellung eines induktiven Energieübertragungssystems. Die Verfahren sollen durch geeignete Maßnahmen für die industrielle Fertigung befähigt werden. Neben praktischen Versuchen ist auch der prototypische Aufbau von Demonstratoren vorgesehen. Mögliche Aufgabenstellungen können sein:
- Einarbeiten in die Technologien für die kontaktlose Energieübertragung
- Analyse von verschiedenen Systemaufbauten der Marktbegleiter
- Adaption bestehender Konzepte aus dem Elektromaschinenbau auf den neuen Anwendungskontext
- Entwicklung und Konzeption geeigneter Vorrichtungen und Aufbau von Demonstratorsystemen
Hinweise und Bewerbung:
- Bearbeitung der Aufgaben im studentischem Team
- Strukturierte und selbstständige Arbeitsweise
- Bewerbungen bitte per E-Mail mit Lebenslauf und aktueller Fächerübersicht an info@seamless-energy.com
Ansprechpartner:
Maximilian Kneidl
Maximilian Kneidl, M.Sc. info@seamless-energy.com
