")
Ausgangslage:
Die digitale Transformation der Produktion verspricht, die Produktivität im Inland zu steigern und neue Geschäftspotenziale zu erschließen. Das Revolutionäre an Industrie 4.0 ist nicht allein die Digitalisierung der Produkte und ihrer Produktion, sondern die Möglichkeit technische Systeme in Echtzeit zu vernetzen. Die dadurch gewonnenen Daten können mit Methoden des maschinellen Lernens (ML), einem Teilgebiet der Künstlichen Intelligenz (KI), nutzbringend ausgewertet und daraus neues Wissen generiert werden. Mit zunehmender Rechen- und Speicherleistung durch Cloud Computing aber auch in lokalen Edge-Geräten lassen sich komplexe Algorithmen, etwa Verfahren des Deep Learnings, zur Prozess- und Qualitätsverbesserung im Produktionsumfeld einzusetzen.
Eine hinreichende Datenbasis stellt eine wesentliche Voraussetzung für die Anwendbarkeit maschineller Lernverfahren dar. So wird die Güte der resultierenden ML-Modelle v.a. von der Qualität und Quantität des Datensatzes bestimmt. Bei unzureichender Datenreife kann zum einen die nachträgliche Integration geeigneter Sensoren zielführend sein. Zum anderen kann die Anpassungen bestehender Anlangenschnittstellen und SPS-Programmen den Zugang zu weiteren Rohdaten eröffnen. Bisher befassen sich jedoch nur wenige wissenschaftliche Arbeiten mit der systematischen Analyse und Bewertung der Datenreife sowie der Ableitung von Maßnahmen zu deren zielgereichteten Erhöhung.
Aufgabenstellung:
Im Rahmen dieser Arbeit soll – ausgehend von einschlägigen Vorarbeiten – ein methodischer Ansatz entwickelt werden, anhand dessen die Datenreife im produktionstechnischen Umfeld systematisch analysiert und bewertet werden kann. Der ermittelte Ist-Zustand bildet wiederum die Basis, um Maßnahmen zur Erreichung eines anvisierten Soll-Zustands abzuleiten. Als praktisches Anwendungsbeispiel dient im vorliegenden Fall die automobile Elektromotorenproduktion, die im Zuge der E-Mobilität immer mehr an Bedeutung gewinnt und damit großes Potential für datengetriebene Optimierung birgt. Daraus ergeben sich folgende Arbeitspakete:
- Einarbeitung in die relevanten Grundlagen der Künstlichen Intelligenz, insb. des Maschinellen Lernens
- Übersicht über bestehende KI- bzw. ML-Anwendungen in der Produktion
- Identifizierung und Vergleich bestehender Ansätze zur Bewertung der Datenreife, etwa Reifegradmodelle im Bereich Industrie 4.0 oder Data Analytics (z.B. Gartner’s Analytics Maturity Model)
- Ableiten eines methodischen Ansatzes zur systematischen Analyse, Bewertung und Erhöhung der Datenreife in der Produktion unter Berücksichtigung sowohl technischer als auch wirtschaftlicher Gesichtspunkte; dabei Einbezug von Maßnahmen und Hilfsmitteln, durch die der ermittelte Ist-Zustand systematisch in den anvisierten Soll-Zustand überführt werden kann (z.B. durch die zielgerichtete Integration weiterer Sensorik oder die Anpassung bestehender Anlagenschnittstellen)
- Validierung der Methodik anhand eines ausgewählten Fallbeispiels
Nähere Informationen gerne auf Anfrage im persönlichen Gespräch. Beginn, Umfang und genaue Ausrichtung der Arbeit erfolgen nach Absprache und persönlichem Interesse.
Hinweise und Bewerbung:
- Forschung im Trendthema Industrie 4.0, KI und ML
- IT-Affinität vorausgesetzt, zielgerichtete Einarbeitung anhand von Vorarbeiten möglich
- Bewerbungen bitte per E-Mail mit Lebenslauf und aktueller Fächerübersicht an andreas.mayr@faps.fau.de
Ansprechpartner
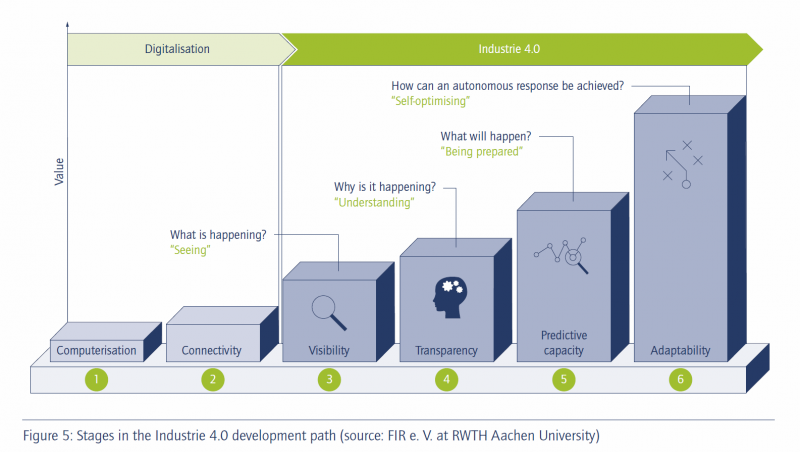
Beispielhaftes Industrie-4.0-Stufenmodell nach Schuh et al.